
Centralized teams face the challenge of managing an influx of petabytes of observability data and organizing it so that users can effectively find and use the data for real-time decision making. They're in a tight spot, balancing control, maintainability, performance, and data security with giving users instant data access to contextually relevant data.
To ensure effective utilization of observability data and meet data governance requirements at the same time, organizations must preserve both technical and business context across massive, fast-moving data streams. This is a complex challenge:
- Maintaining data context: Relating logs, metrics, and traces across domains requires advanced correlation mechanisms. Yet, inconsistent tagging practices across teams and services lead to fragmented views and blind spots.
- Maintaining business context: Observability data often relies on enrichment rules to inject business metadata, such as service owners, cost centers, or deployment tags. These enrichment rules are typically static and hardcoded, requiring constant updates to keep pace with shifting organizational structures, service ownership, and evolving business priorities.
At enterprise scale, these challenges are magnified. Organizations often have hundreds of teams and thousands of users who require access to observability data, each with different needs and use cases. Centralized teams are expected to provide real-time access to relevant data while managing an ever-growing number of filters and governance rules. Manually maintaining and rolling out thousands of static filters across dynamic environments is not only time-consuming; it simply doesn’t scale. To remain effective, organizations need an approach to organizing their data that is dynamic, easy to manage, and empowers users with self-service access to the right data in the right context, without compromising compliance or security.
Dynatrace addresses this with the introduction of Segments, a dynamic, multidimensional, enterprise-grade approach to data segmentation that’s applied at query time. This allows centralized teams to provide smart filtering that removes noise by applying user, team, or application-specific context, while at the same time reducing their maintenance effort.
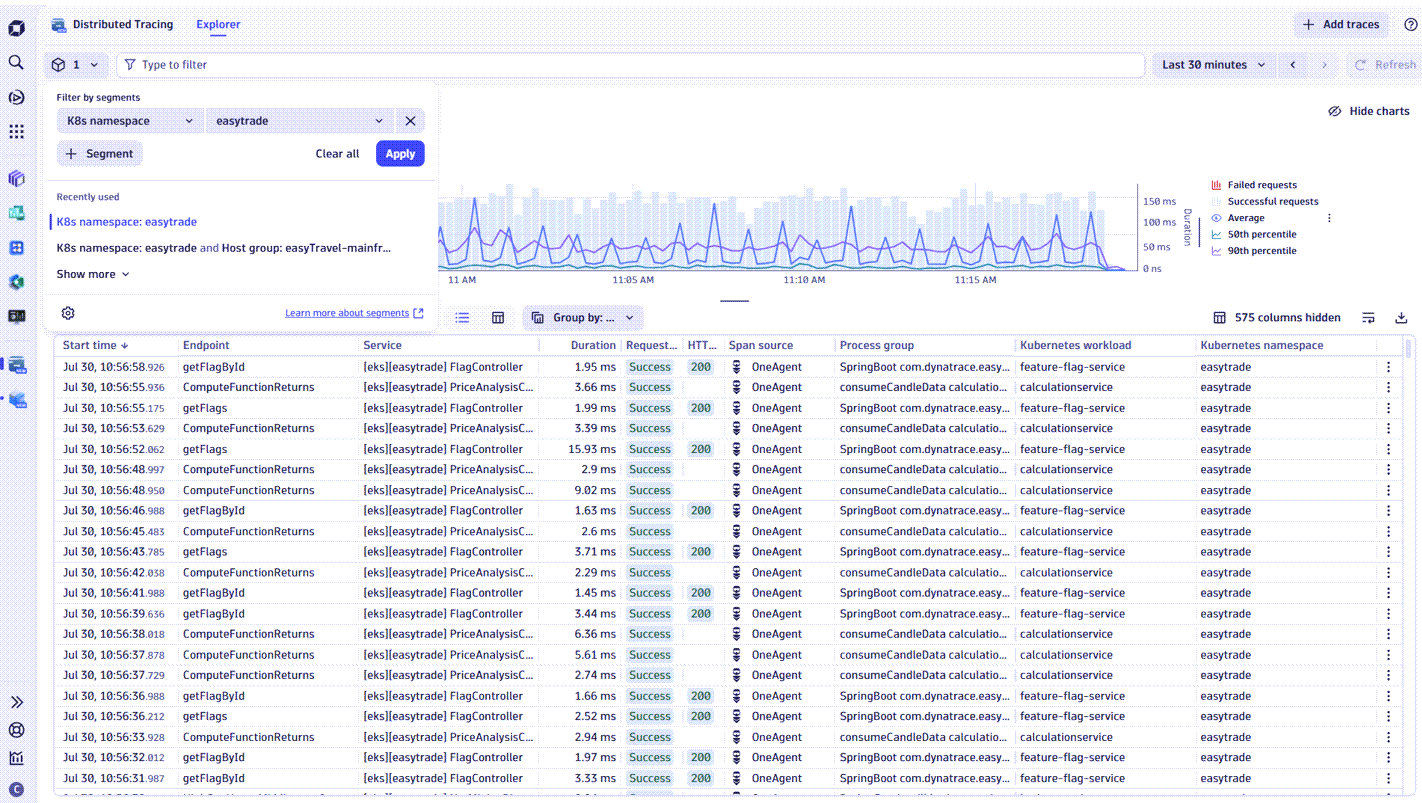
Decoupling backend data organization from frontend data utilization
Dynatrace is built from the ground up to meet the scale and manageability demands of modern cloud- and AI-native enterprises. With organizations generating petabytes of telemetry daily, Dynatrace ensures real-time ingestion, exploration, and analysis across all data types. Its architecture supports thousands of users across ITOps, SRE, developers, platform engineering, and business teams, while remaining efficient and easy to maintain.
While other observability solutions struggle with scalable, use–case–optimized data segmentation and robust access controls, Dynatrace delivers enterprise-grade manageability with full flexibility to meet any requirements. It decouples compliance and security from day-to-day data usage, enabling both control and agility at scale.
To support this, Dynatrace introduces three core concepts that feature segments as a key part of the solution:
- Data partitioning (buckets): Organize data logically to meet performance, compliance, and retention requirements. Think of a bucket as a folder in a filesystem. Use buckets to group telemetry data that naturally belongs together, for example, data from the same region, environment, or with the same sensitivity classification.
- Data access (IAM): Stay flexible and meet compliance and security demands by defining fine-grained access to data and Dynatrace platform capabilities based on a user’s context. Use IAM to manage fine-granular permissions, enforcing enterprise-grade governance.
- Data segmentation (segments): Enable real-time filtering across massive data sets without the need to create thousands of individual rules. Segments are fully governed by existing access controls, ensuring that users only see the data they’re authorized to access.
Use segments across your organization
Segments bring business context to observability data and are consistently available across the Dynatrace platform. The key benefits of using segments are:
- Dynamic, not static: Segments adapt automatically using variables, keeping filters relevant as environments evolve. New services, Kubernetes namespaces, and more are picked up without manual updates. Segments are multidimensional, so users can combine them to zoom in on their data.
- Performance-optimized pre-filters: Applied at query time, segments scope queries to only the selected data segment, reducing overhead and increasing efficiency.
- Establish shared, global data views, aligned to business logic: Structure data segments, for example, by data ownership region, business unit, environment, or application. Provide a consistent source of truth across the organization.
- User-created context: By combining centrally managed segments with their own custom filters, users can personalize their views without involving the centralized team.
- Built for scale: Real-time filtering across petabyte-scale data volumes, by thousands of users, without compromising performance.
Consider the following examples, how different roles can use the same set of segments to tailor their view of shared data to their specific needs.
- An IT Ops team looking to quickly assess infrastructure health in a specific region does this by combining segments for region with host group, cloud provider, or Kubernetes cluster, instantly narrowing the scope.
- Developers troubleshooting a web app select the segment focusing on all data related to this particular app, and combine it with an additional filter for Kubernetes namespaces to zoom in on logs, metrics, and traces tied to that exact deployment. They then layer on details like error types or device models to pinpoint exactly where issues occur. This allows them to rapidly identify issues and improve stability and user experience.
Although both teams work from the same unified observability dataset, segments dynamically apply each user’s individual context at query time, ensuring they only see what’s relevant.
Tip: To further customize the Dynatrace experience for different roles, familiarize yourself with Launchpads, our central entry point for users that consolidates relevant resources and makes their Dynatrace experience more personal and relevant. Learn more about Launchpads.
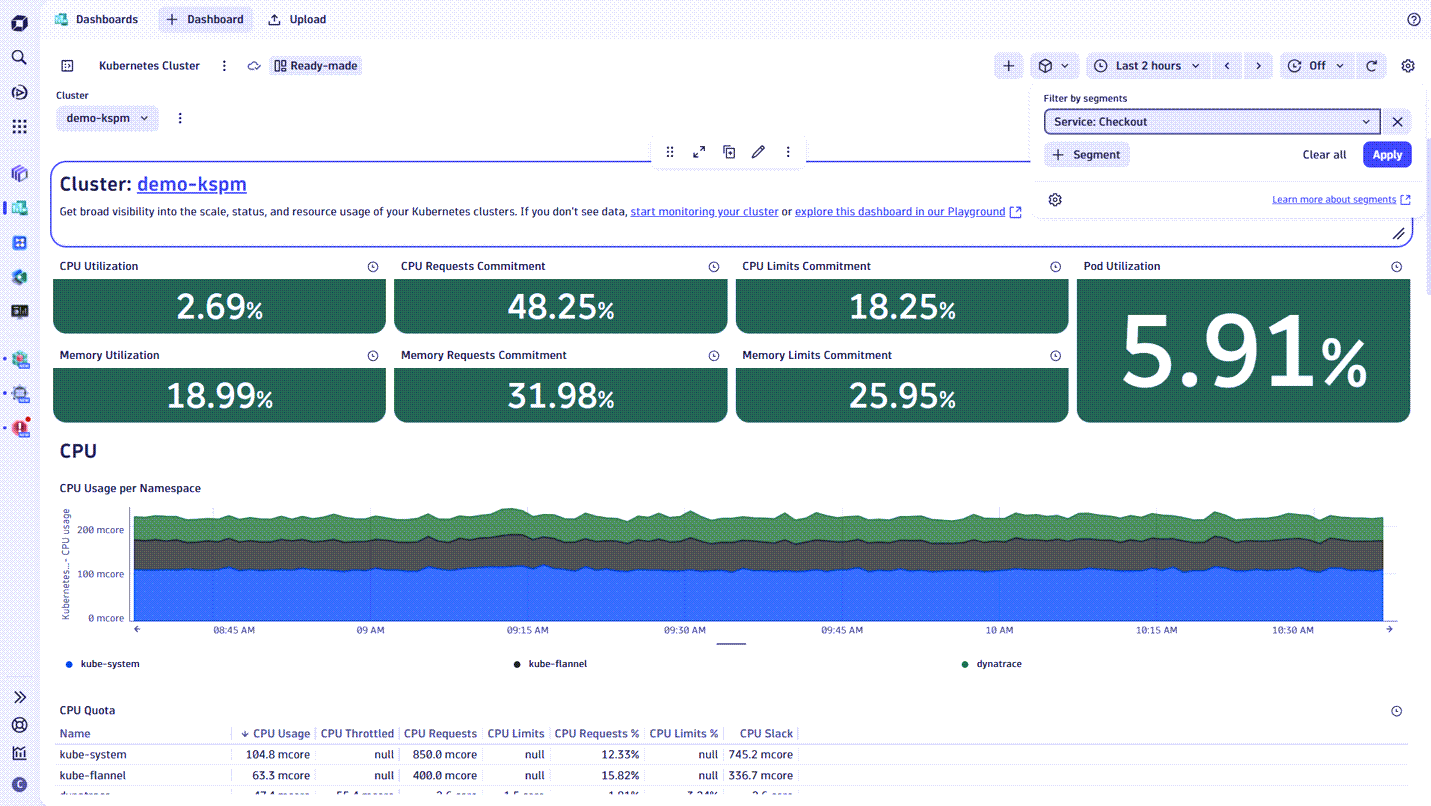
Discover how to leverage segments in your organization
For more on how to get the most out of segments, explore our documentation and these helpful resources:


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum