
Complex systems and IT environments generate increasingly more observability data and signals than ever before. Not only do observability platforms need to manage the scale of this data efficiently, they must also provide safeguards that allow their customers to control and protect their sensitive data in compliance with an evolving regulatory landscape while not reducing the value they provide to their users and customers, whether it’s personal data, payment data, health information, or any other sensitive data requiring protection.
In this blog post, you’ll learn how Dynatrace allows you to manage observability data at scale by providing sensitive data handling capabilities across the entire data lifecycle on the Dynatrace platform. Preventing sensitive data from leaving the customers environment, using OpenPipeline™ to efficiently enrich, contextualize and ingest huge volumes of data, leveraging Grail™ data lakehouse for unified storage for all data types, with a wide range of regions to select from to meet your data residency needs, and leveraging other platform capabilities such as controlling access to data, or enabling to delete only the selected records permanently, helps significantly reduce the complexity of managing different data types typically stored in silos.
Why sensitive data management is important
Whether a bank, government, or airline, observability is no longer optional for any organization’s IT systems that must provide high-quality and secure services to its customers and end-users. These systems generate vast amounts of data, and sensitive data might be embedded in such large-scale volumes of data.
To maintain customer trust and comply with stringent regulatory requirements, such as GDPR or HIPAA, organizations need to manage sensitive data appropriately, not only in their own IT environment but also in their observability platform and other third-party services. Sensitive data isn’t required for the majority of observability use cases. Organizations should control which data is captured, how it’s processed, where it’s stored, and who can access it. Additionally, organizations must promptly address data subject and privacy rights requests and adhere to retention periods, all in line with their privacy policies and regulations.
Manage sensitive data at scale in complex IT environments
Big IT environments often use thousands of apps and digital services managed by different teams. Each app generates a significant amount of observability data, often with different structures and sensitive data types. In such complex environments, it’s essential to not only detect sensitive data and configure how the observability platform handles such data but also validate that the configuration works as intended and permanently remove selected sensitive data, if needed, without compromising the remaining data and the larger dataset.
End-to-end sensitive data handling in Dynatrace
The Dynatrace data lifecycle consists of five steps.
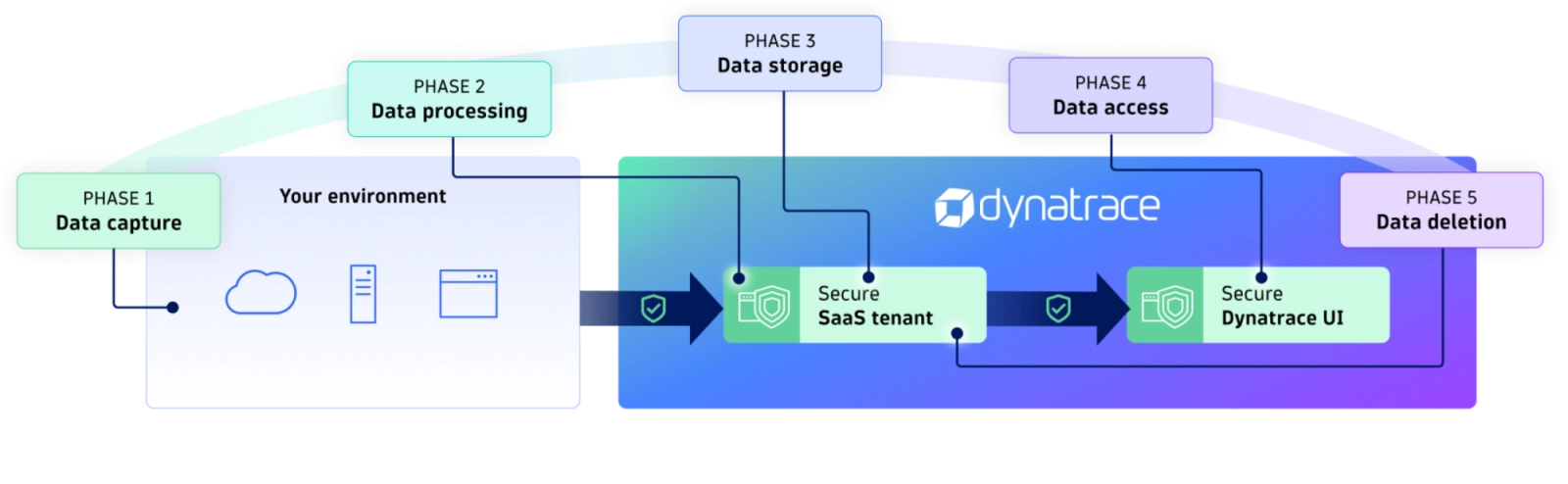 While all data sent to Dynatrace is encrypted in transit and storage, each step provides you with the capabilities and controls needed to manage your sensitive data. While this blog post focuses on privacy controls and managing sensitive data in Dynatrace, you might be interested in how Dynatrace protects your data overall. Check our Trust Center for an overview or Dynatrace Documentation for the complete list and description of security and privacy controls in Dynatrace.
While all data sent to Dynatrace is encrypted in transit and storage, each step provides you with the capabilities and controls needed to manage your sensitive data. While this blog post focuses on privacy controls and managing sensitive data in Dynatrace, you might be interested in how Dynatrace protects your data overall. Check our Trust Center for an overview or Dynatrace Documentation for the complete list and description of security and privacy controls in Dynatrace.
1. Data capture
When using Dynatrace OneAgent® and Dynatrace Collector for OpenTelemetry data, sensitive data matching the masking rules is irreversibly redacted at its first contact with Dynatrace and doesn’t leave the monitored environment.
This is often a crucial requirement for organizations operating in highly regulated industries. Take, for example, a financial institution using Dynatrace Log Analytics to monitor and analyze SWIFT message logs across its global infrastructure. These logs and other user behavioral data are essential for tracking transaction flows, detecting anomalies, and ensuring regulatory compliance. However, given the sensitive nature of the data, such as account identifiers and payment instructions, they must enforce robust privacy controls to comply with regulations like GDPR and other industry standards. One of those rules is that sensitive data must not leave their environment.
To address this, the institution leverages Dynatrace’s multi-layered data masking capabilities. Before log data leaves the environment, Dynatrace OneAgent applies user-configured masking rules at capture to, for example, allow for the redacting of the account number, name, date of birth, and address of the account holder and beneficiaries.
2. Data processing
Data sent to Dynatrace is processed in OpenPipeline™, a powerful solution for ingesting and enriching huge volumes of data quickly and cost-effectively, while allowing configuration to allow secure and compliant collection and processing. With OpenPipeline, organizations can define processing rules that automatically mask or redact sensitive data such as credit card numbers, email addresses, or IP addresses, regardless of the source. This approach allows flexible, centralized masking, protecting sensitive data before it‘s stored or made available for analysis.
3. Data storage
Data localization and residency are becoming increasingly important for organizations to address various strategic, regulatory, and operational requirements. By keeping data within specific geographic regions, organizations can comply with local laws, regulations, and sector-specific requirements. For this purpose, Dynatrace can be deployed to AWS, Azure, and Google Cloud regions across the globe and thus support most of its customers in storing their data within their preferred region.
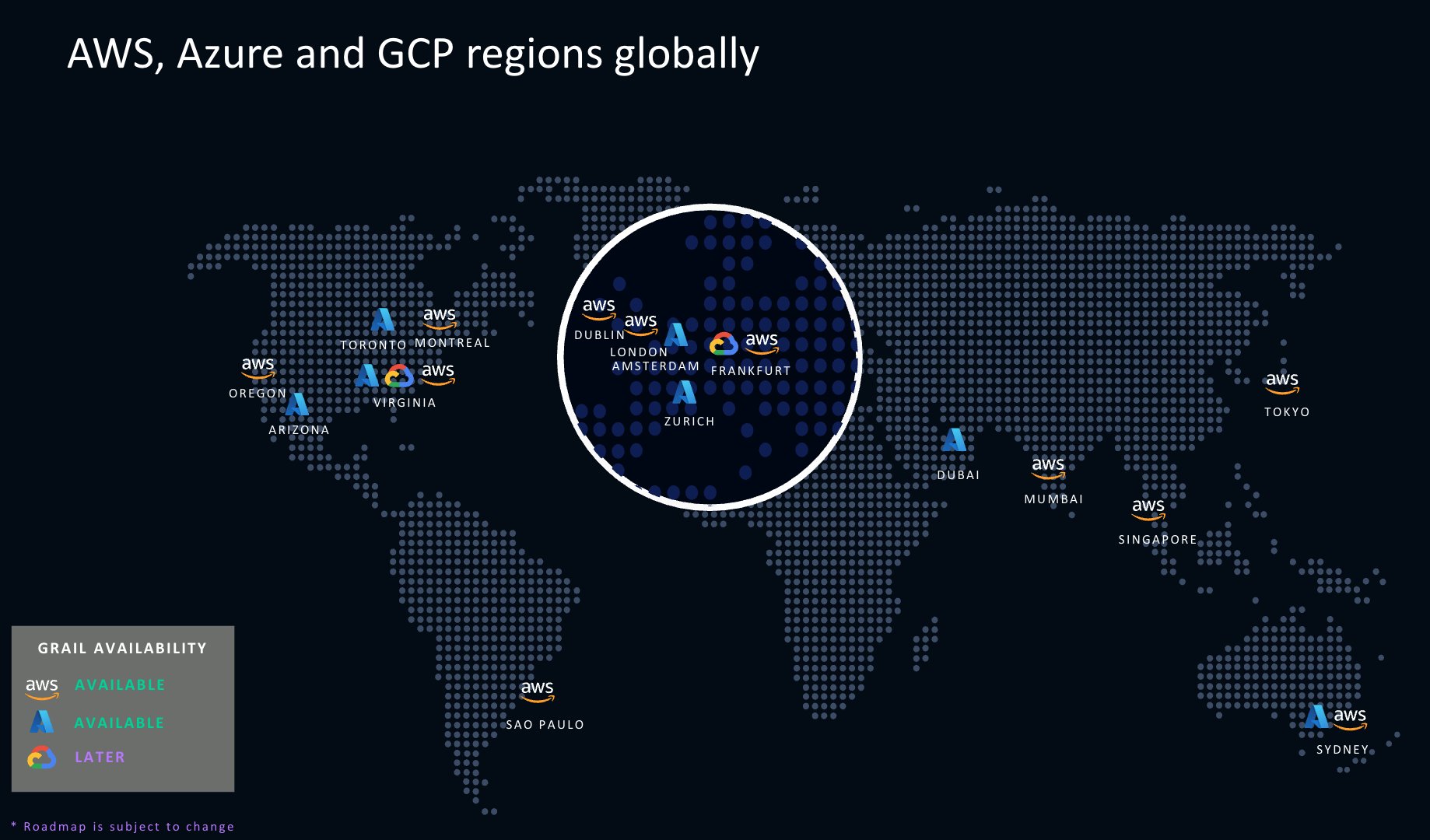
Data ingested into Dynatrace is stored in the Grail™ data lakehouse, a unified data storage system for unifying and contextually analyzing observability, security, and business data at any scale.
In addition to the location where sensitive data is stored, it’s crucial not to store such data for longer than needed. Dynatrace allows configurable retention periods for custom Grail buckets, such as up to 10 years for logs and distributed traces.
Some customers also store logs for audit purposes. Depending on your country and industry, you might be required to store audit logs for five or even up to 10 years, a practice your Dynatrace tenant supports.
The logs stored in Grail are always accessible by any app and user who has permission to do so. This minimizes the time and cost in case historical data must be accessed by an auditor, as there is no such process of rehydration or concept of hot/cold-storage tiers.
Dynatrace makes subject rights management easy with the Privacy Rights app. Authorized users can efficiently search for all personal data related to a specific individual, review the results, and approve export or deletion requests in a secure, auditable workflow meeting regulatory deadlines. This helps organizations fulfill data subject rights requests, such as those required under GDPR and CCPA.
4. Data access
Granular and configurable data access is essential for protecting sensitive data and ensuring only authorized users can view and interact with stored data. Grail access in Dynatrace is managed through a flexible, fine-grained permission system that allows administrators to control who can access data at multiple levels, from buckets to tables and records down to the field level.
A healthcare diagnostics provider partnered with us to enhance their observability while ensuring HIPAA compliance and protecting PHI/PII. In addition to masking and redacting PHI/PII fields at ingest, they configured granular field-level access controls, allowing their teams to view only the data relevant to their roles. This way, Dynatrace empowers providers with secure, compliant, actionable insights from their logs without compromising patient privacy.
5. Data deletion
Dynatrace allows organizations to meet strict privacy and compliance requirements by supporting hard deletion of individual records in Grail. This capability, available via Grail API and Privacy Rights, ensures that information can be securely and permanently removed at the record level, without impacting the integrity or availability of other valuable data. An audit trail is maintained for deletions directly executed through the API and those orchestrated by the Privacy Rights app. Unlike soft deletion, which might only hide data, hard deletion in Grail guarantees that deleted records are irreversibly erased, reducing the risk of unauthorized access and supporting full regulatory compliance.
Sensitive Data Center
Later this year, Dynatrace will start integrating its sensitive data handling capabilities into the new Sensitive Data Center* to help streamline the management of sensitive data. In the first step, we’ll combine the existing Privacy Rights with the planned, and currently in development, Sensitive Data Scanner*.
Sensitive Data Scanner adds another level of protection to Dynatrace’s existing sensitive data masking capabilities. It monitors Grail for unintentionally ingested sensitive data in logs, allowing customers to validate their masking configuration, quickly identify and respond to inconsistencies, and take precise and targeted corrective action for future data ingestion and sensitive data that has already been ingested, such as adjusting access permissions and retention periods, deleting sensitive data, and updating masking rules to prevent sensitive data types from being stored in the future.
Summary
You’ve learned about how Dynatrace helps you manage sensitive data securely and in compliance with regulations throughout its lifecycle. Dynatrace focuses on privacy from the moment data is captured, using advanced masking techniques to prevent sensitive information from leaving the environment, and through centralized data processing and unified data storage, including supporting data residency and retention controls. Dynatrace supports compliance for many global and industry-specific standards. Fine-grained access controls and hard-deletion capabilities further empower organizations to manage data governance and fulfill privacy obligations like GDPR and CCPA. Overall, Dynatrace offers a comprehensive, privacy-first approach to observability that aligns with operational needs and regulatory demands.
* This blog post contains forward-looking statements. These statements reflect current views and assumptions, but results might differ due to various risks or plan changes.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum