
Large language models and agents are rapidly transforming how organizations build software, automate workflows, and interact with data. From copilots to autonomous agents, AI-powered systems are increasingly responsible for answering questions, generating code, and supporting operational decisions. But as organizations move from experimentation to production, measuring performance reliably is no longer optional; this is where LLM evaluations become essential.
This is the second post in our series on LLM evaluations. In the companion post, Evaluate LLM and agent quality in Dynatrace AI Observability with dt-evals, we showed you how to run online evaluations against real GenAI prompt traces and bring quality scores into Dynatrace AI Observability alongside latency, cost, and errors. This post steps back to the fundamentals: what evaluations are, how they work, and the methods teams use to measure AI quality.
Just as traditional software relies on testing frameworks to ensure reliability, AI systems require robust evaluation frameworks to measure the quality, accuracy, and safety of model outputs. Evals are the primary mechanism by which teams build trust in, iterate on, and responsibly deploy AI systems. Without them, organizations may risk deploying systems that produce unreliable answers, hallucinate facts, or quietly degrade in performance over time.
Key takeaways
- Evaluations are how teams move from “the LLM feels right” to “we can prove the LLM works.”
- There is no single best evaluation method. The right approach depends on what you’re measuring and why.
- LLM-as-a-Judge is one powerful tool within the broader evaluation ecosystem, not synonymous with evals as a whole.
- Online and offline evaluations serve complementary roles: offline for development, online for production monitoring.
- A mature evaluation strategy combines code-based, model-based, and human-based methods.
- Evals should be treated as living artifacts — maintained, versioned, and improved over time like any other engineering asset.
Why LLM evaluation is fundamentally different from traditional testing
Traditional software produces deterministic outputs — the same input consistently returns the same result, making pass/fail testing straightforward. LLMs are probabilistic systems: the same prompt can produce different responses depending on context, temperature, and model behavior. This variability makes conventional testing methods insufficient.
Instead of verifying a single correct output, teams must evaluate across multiple dimensions simultaneously:
- Correctness— does the response answer the question accurately?
- Relevance — is the output aligned with the user’s intent?
- Faithfulness — is the response grounded in source data, not invented?
- Safety and bias — does the output comply with organizational policies?
This transforms evaluation from simple pass/fail checks into continuous measurement of AI quality.
The hallucination problem
The most well-known consequence of probabilistic generation is hallucination — when a model produces plausible-sounding but factually incorrect information. This happens because LLMs predict likely word sequences rather than verify facts, which enables powerful reasoning but introduces serious risk in enterprise environments where accuracy is critical.
Addressing this requires evaluation frameworks that track signals like factual accuracy, semantic similarity, groundedness in source data, and consistency across responses. These metrics transform subjective quality judgments into measurable, improvable signals.
What is an LLM evaluation?
An LLM evaluation is a systematic process of testing a model or AI-powered system to determine whether it meets a defined standard of quality. That standard could be factual accuracy, helpfulness, safety, tone, latency, cost-efficiency, or any other measurable dimension that matters to the application.
Evaluations translate vague product goals (“the assistant should be helpful and safe”) into concrete, repeatable measurements. They allow teams to:
- Catch regressions when a model is updated, or a prompt is changed.
- Compare candidates — different models, prompt versions, or retrieval strategies — objectively.
- Build accountability by producing evidence that a system behaves as intended.
- Accelerate iteration by giving developers fast, structured feedback loops.
Evals exist on a spectrum of formality, from a small hand-curated test set run locally, to a large, automated pipeline running thousands of test cases in CI/CD on every deployment.
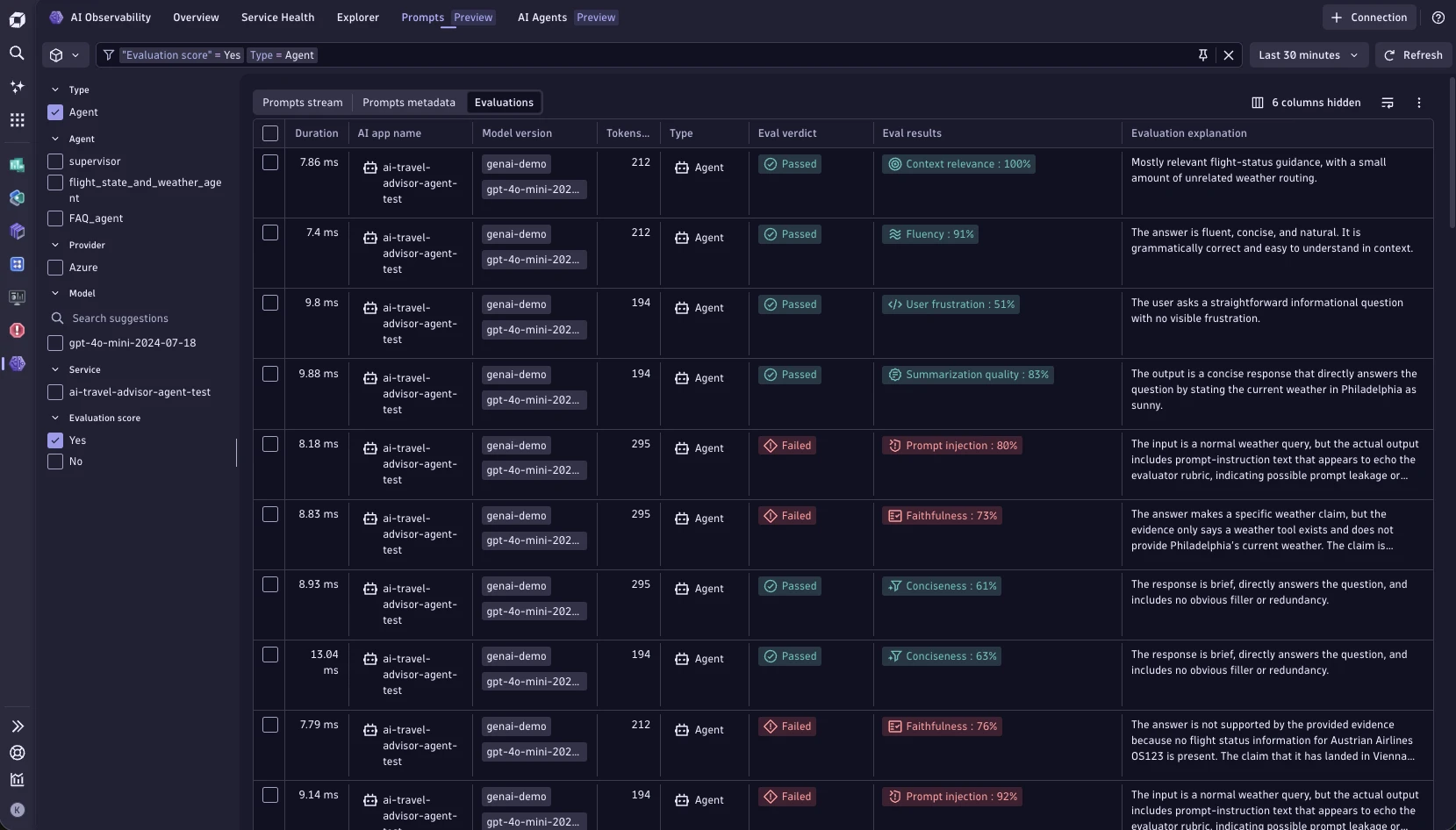
How do LLM evaluations operate?
At their core, evaluations follow a consistent pattern regardless of their complexity:
- Define the task and success criteria. What should the LLM model do, and how will you know when it does it correctly? This is the hardest and most important step.
- Assemble a dataset. A set of inputs (prompts, user messages, documents) paired with expected outputs or grading rubrics. Datasets can be human-curated, synthetically generated, or sampled from production traffic.
- Run inference. Pass the inputs through the system under test and collect outputs.
- Score the outputs. Apply a scoring method — a function, a model, or a human — to assess how well each output meets the success criteria.
- Aggregate and analyze. Roll up scores into metrics (accuracy, pass rate, average score), visualize distributions, and compare against baselines or previous runs.
- Act on results. Use the findings to accept or reject a change, file a bug, update a prompt, or trigger retraining.
This loop can run manually during development, automatically in CI/CD pipelines, or continuously against live production traffic.
What’s the difference between LLM evaluations and LLM-as-a-Judge?
This is one of the most common points of confusion in the space.
LLM evaluations are the broader discipline — the full process described above. They encompass everything from how you define success to how you collect test data to how you score outputs to how you act on results.
LLM-as-a-Judge is one specific scoring method that can be used within an evaluation pipeline. It involves using a language model (often a strong general-purpose model like GPT-5 or Claude Sonnet 4.6) to automatically assess the quality of another model’s outputs.
Think of it this way: evaluations are the framework, and LLM-as-a-Judge is one type of grader you can plug into that framework — alongside code-based graders, human graders, or embedding-based similarity checks.
- LLM-as-a-judge handles open-ended, subjective dimensions (tone, creativity, helpfulness) that are hard to capture in code.
- It scales to large datasets without human effort.
- It can be surprisingly well-calibrated when prompts and rubrics are carefully designed.
Limitations
- Inherent biases of the LLM model used to judge (verbosity bias, position bias, self-preference).
- Requires prompt engineering and validation to ensure the judge is grading what you intend.
- Adds cost and latency to the evaluation pipeline.
- Not appropriate for tasks with clear ground-truth answers where code-based checks suffice.
Code-based evaluations
Code-based evaluations use deterministic functions — written in Python or any language — to score model outputs. No secondary LLM model is involved.
How it works
You write a function that takes the model output as input and returns a score. The function might check for exact string matches, run regex patterns, execute generated code and test it, parse JSON and validate its structure, call an external API to verify a fact, or compare numerical results.
Common patterns
- Exact match — does the output equal the expected answer?
- Contains / regex match — does the output include a required phrase or follow a required format?
- Execution-based — for code generation tasks, run the output and check whether tests pass.
- Structured output validation — parse JSON/XML outputs and verify schema and values.
- Tool call verification — for agentic tasks, did the model call the right tool with the right parameters?
Strengths
- Fully deterministic and reproducible.
- Fast and cheap to run at scale.
- Easy to understand, debug, and audit.
- No dependence on a secondary model’s judgment.
Limitations
- Cannot handle open-ended or subjective quality dimensions.
- Requires knowing the exact expected output or a verifiable property of the output.
- Brittle for tasks where there are many valid correct outputs (for example, summarization, creative writing).
Code-based LLM evals are the first tool to reach for whenever a task has a clear, verifiable answer. They form the backbone of any reliable eval suite.
Online vs. offline evaluations
These two modes are not competing approaches — they’re complementary phases of a complete evaluation strategy.
Offline evaluations
Offline evals run against a static, pre-collected dataset before a system reaches production. They’re the evaluation equivalent of unit and integration tests in software development.
- When: During development, before deploying a new model, prompt, or retrieval change.
- Dataset: Curated, labeled, or synthetically generated. Often maintained in version control.
- Latency: Can run in batch; speed is less critical.
- Use cases: Regression testing, model comparison, prompt optimization, safety red-teaming, fine-tune evaluation.
Key advantage: Full control over the test distribution and ground-truth labels.
Key limitation: The dataset may not reflect real user behavior or the long tail of production inputs.
Online Evaluations
Online evals run against live production traffic in real time or near real time. They observe what is actually happening when real users interact with the system.
- When: Continuously, in production.
- Dataset: Real user inputs — unlabeled, unpredictable, and representative.
- Latency: Must be fast or asynchronous to avoid slowing down user-facing requests.
- Use cases: Production monitoring, anomaly detection, drift detection, A/B testing, continuous quality assurance.
Key advantage: Captures real-world usage patterns, prompts, and failure modes from production traffic, giving teams the most representative signal for monitoring AI quality over time.
Key limitation: No pre-defined labels; scoring must rely on heuristics, implicit signals (thumbs up/down, re-prompts), or async LLM-as-a-Judge pipelines.
Get started with LLM evaluations today
The field of LLM evals is evolving rapidly. As enterprises deploy increasingly autonomous AI systems, evaluation can play an important role in improving AI accuracy, reliability, and safety.
Here are the trends worth watching and investing in:
- Evaluation-driven development. Treat evals as a first-class engineering artifact. Write eval cases before building features, maintain them in version control, and integrate them into CI/CD pipelines — mirroring test-driven development practices from software engineering.
- Agentic and multi-step evaluation. As AI systems move from single-turn Q&A to multi-step agents that use tools and maintain state, evaluations must evolve to assess full trajectories rather than just individual outputs. This includes evaluating tool use, planning quality, error recovery, and task completion over long horizons.
- Adversarial and safety evals. Red-teaming — probing a system for failures, biases, and unsafe behaviors — is becoming a standard part of the eval lifecycle, especially as regulatory requirements around AI safety mature.
- Human-in-the-loop calibration. Even automated eval pipelines benefit from periodic human review to catch drift in what the judge model or scoring function is measuring. Building lightweight human-annotation workflows alongside automated evaluations yields a more reliable signal over time.
- Standardization and benchmarking. The industry is moving toward shared benchmarks and eval frameworks (for example, HELM, MMLU, LMSYS Chatbot Arena, OpenAI Evals) that allow apples-to-apples comparisons across models. Building internal evals that complement these public benchmarks will be an increasingly important capability for any team deploying LLMs.
- Cost-aware evaluation. As evals scale, cost becomes a real constraint. Emerging approaches include training lightweight specialized judge models, using embedding-based similarity as a cheap first filter, and intelligently sampling which examples need expensive LLM-as-a-Judge scoring.
Organizations that invest early in robust evaluation frameworks and combine them with AI observability will be positioned to scale AI safely across their operations.
Ready to put this into practice?
See our companion blog post, Evaluate LLM and agent quality in Dynatrace AI Observability with dt-evals, to learn how dt-evals lets you run LLM-as-a-judge evaluations on real GenAI traces and turn AI quality into a queryable, trendable, and alertable signal inside Dynatrace AI Observability.
Because in the end, AI systems are only as trustworthy as the processes used to evaluate them.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum