
Imagine that your critical services have been running for weeks without incident when suddenly your Tomcat cluster is stuck and your service completely fails. This situation represents an Ops team’s worst nightmare. In such a situation, the Ops team must react quickly to find the root cause of the service outage and figure out how best to remediate the problem.
Davis®, the Dynatrace AI causation engine, is the ideal Ops tool for quickly sending alerts for service outages and pinpointing the root causes of such issues.
How to enable Davis service-outage detection
To enable service outage detection for all your services, navigate to Settings > Anomaly detection > Services and enable the detection of service load drops, as shown below. Optionally, you can also enable alerts for unusual service load spikes.
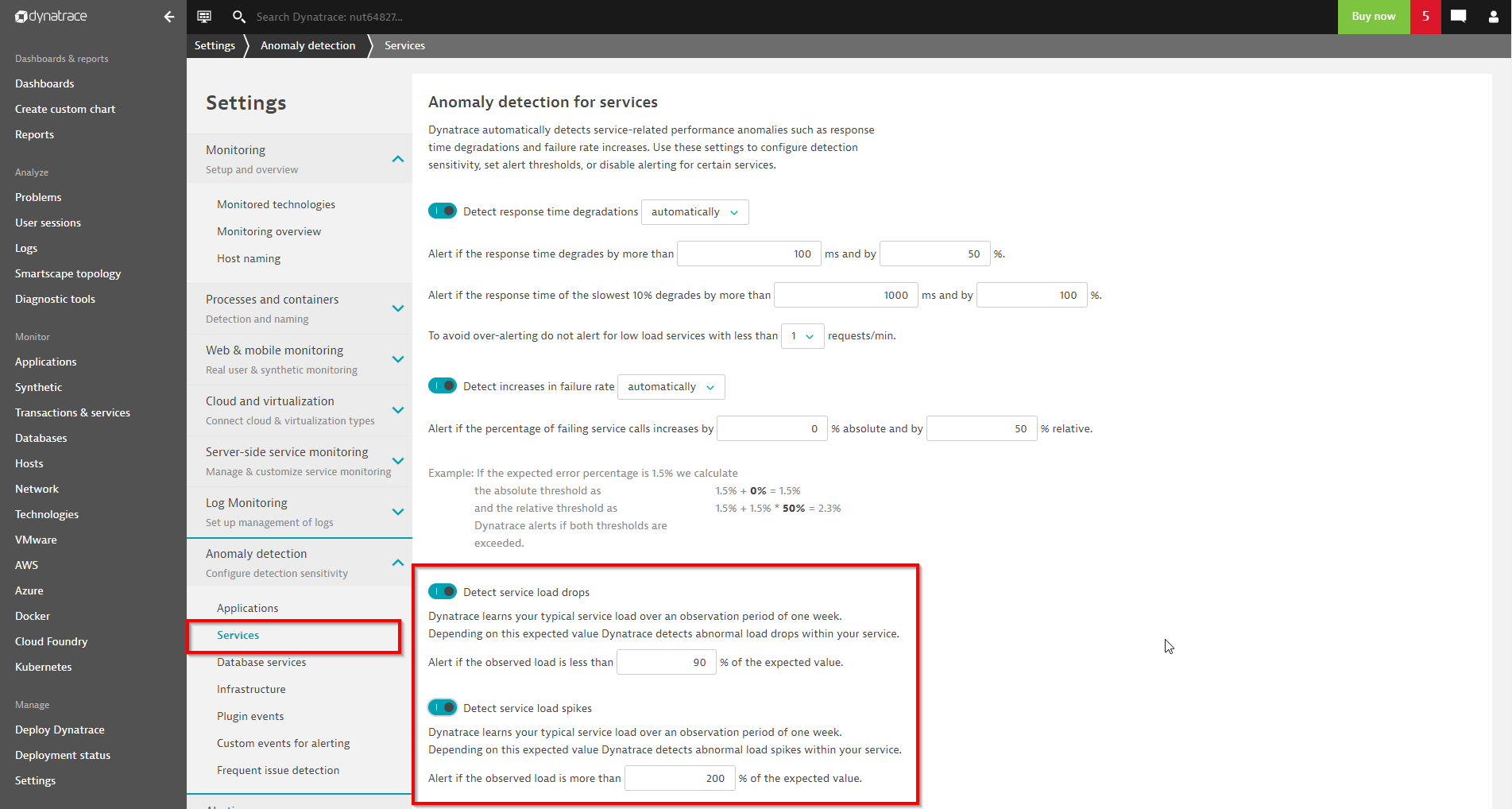
Service load anomaly detection can be enabled and configured at a global level, for individual services, or even for individual key transactions.
Find the root cause faster with service-load baselining
Once a service is detected by Dynatrace OneAgent, Davis automatically learns the typical load of the service over a one-week period. Service outage detection is activated once the one-week learning period has passed and a reasonable seasonal load pattern has been identified.
The service load baseline is a two-cycle pattern of daily and weekly trends. The chart below shows a typical daily service load pattern with clear peaks during business hours. The weekly pattern doesn’t show any peaks or drops during the weekend, so the service load is evenly distributed across all days of the week.
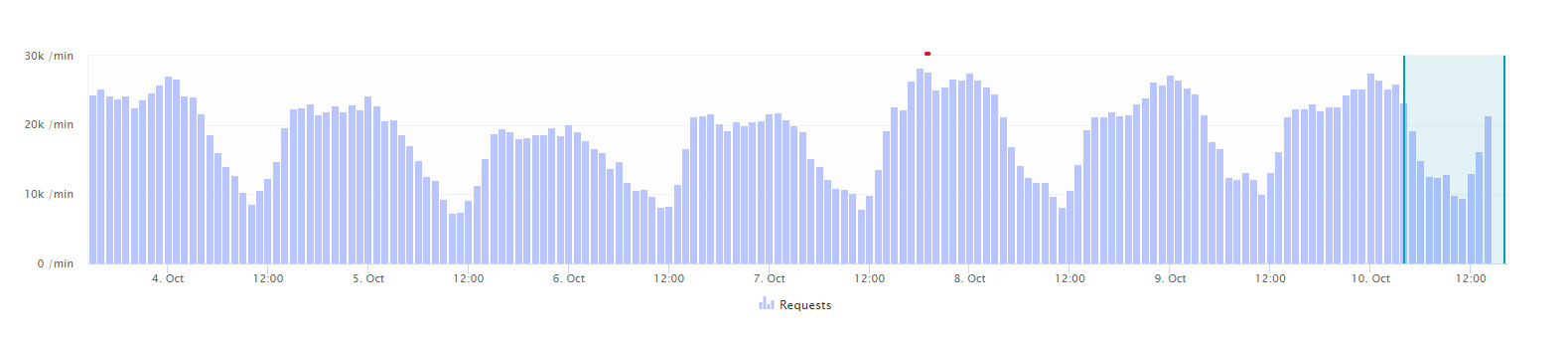
Service-outage detection begins with comparing the learned load baseline with the current levels of incoming service traffic. For example, Davis compares Monday’s service load with last Monday’s service load during the same timeframe. If the current load is much lower than the expected load, Davis immediately raises a Unexpected low load problem. Davis then analyzes all the connected services and underlying infrastructure to find the root cause of the detected service outage.
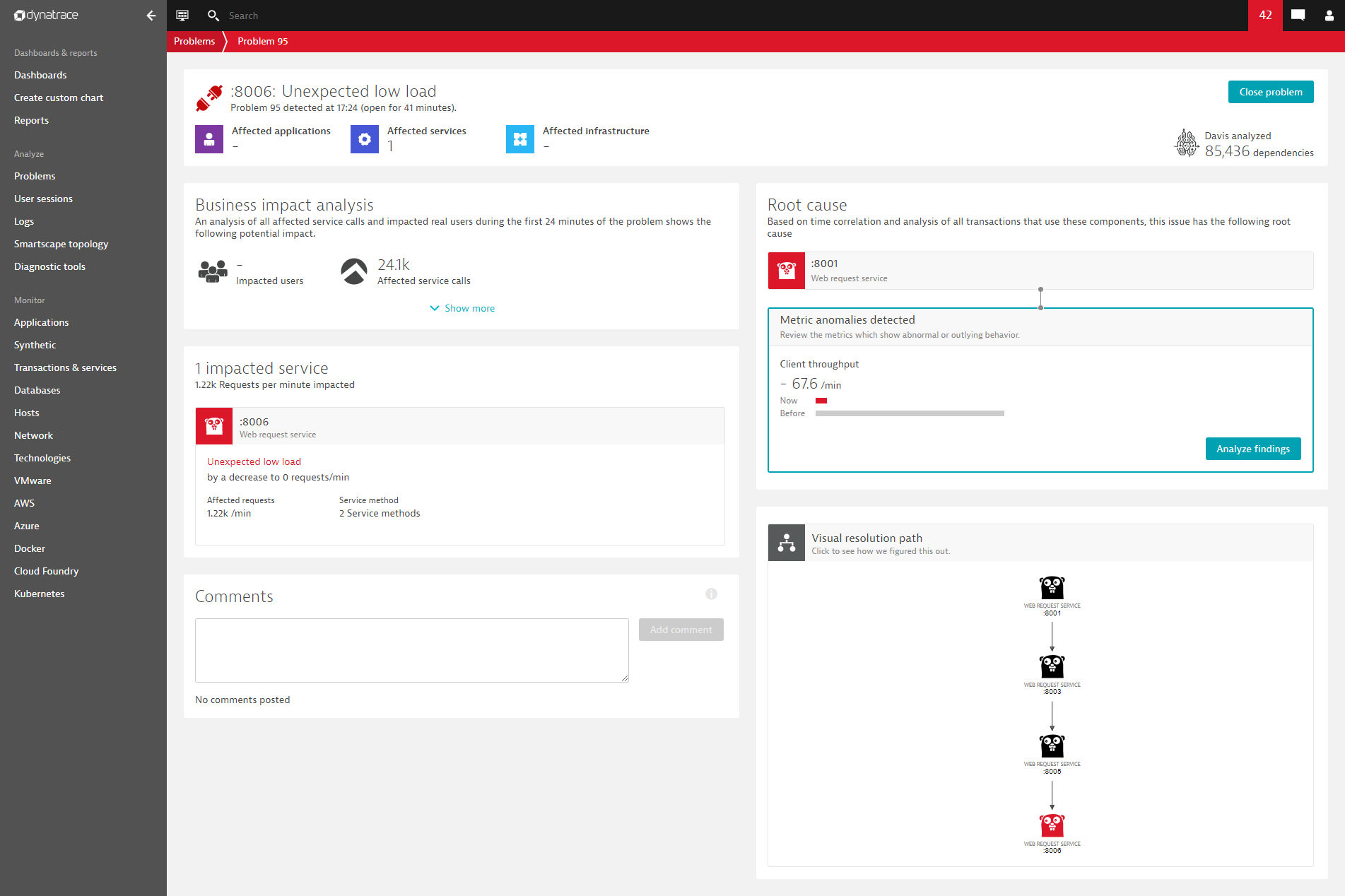
See the example below of a Davis-detected service outage (Unexpected low load). Davis narrows in on the calling service as it shows a reduced number of calls to the back-end service.
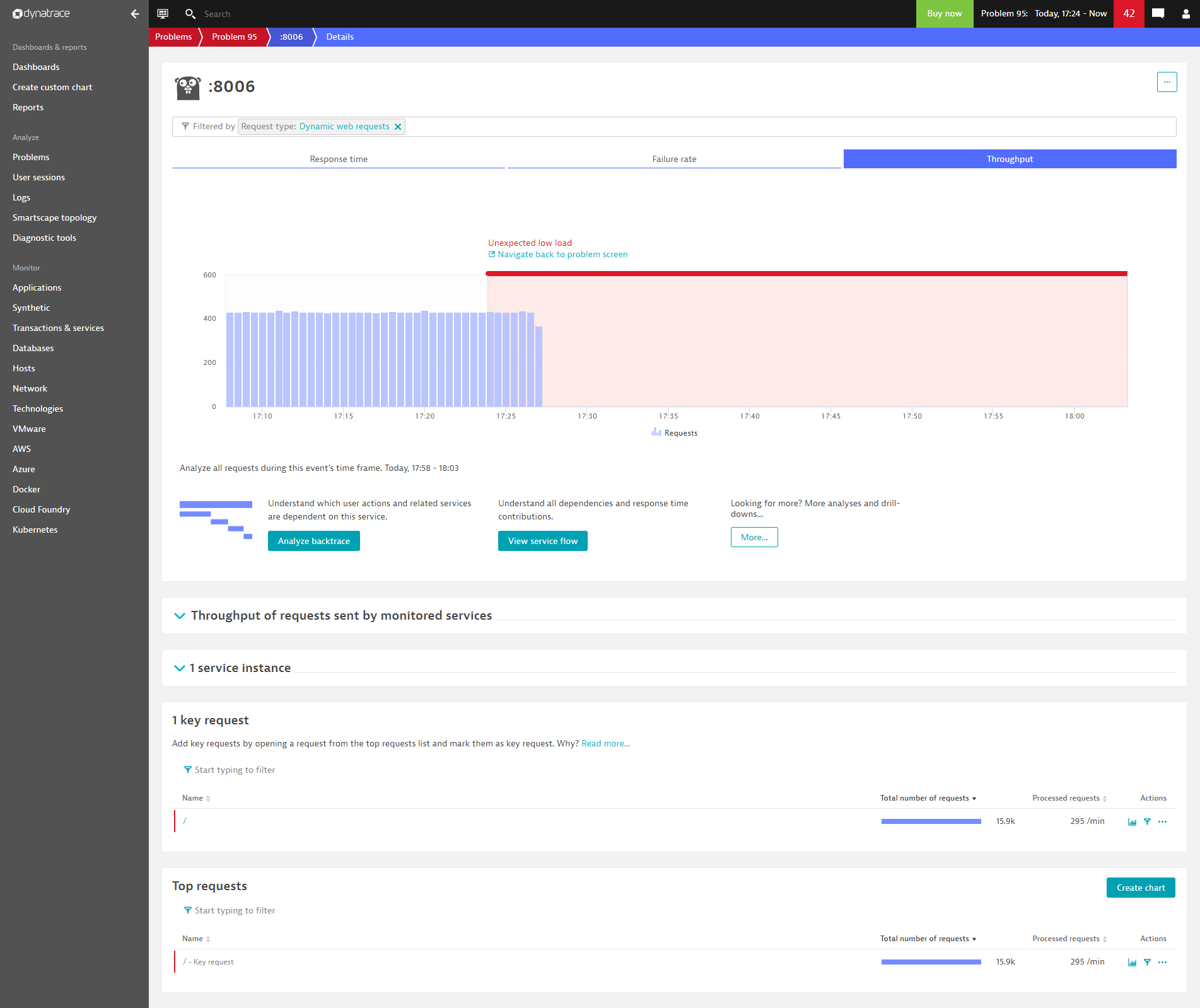
By drilling down into the problem, you can see the missing load on service 8006 that triggered the Davis alert about a service outage. The load dropped to zero, as shown below:
Summary
The newly introduced Dynatrace service-load baseline represents a crucial capability for quickly reacting to business-critical service outages.
It’s good practice to opt into service-load alerting only for those services that are critical for your business and leave the load alerting disabled for non-critical services. Best results can be expected for services that receive continuous, stable load over longer periods of time.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum