
I’ve been working for Dynatrace for just over a year, and have become very impressed with our approach to application problem analysis. So impressed that I decided it was time for me to write about it. Today I’ll attempt to take some of the mystery out of the Dynatrace AI by explaining what it really is. Hopefully, we can answer some of the questions you have about how it works.
AI is all the rage right now. From Microsoft to Apple, companies are starting to recognize the power that AI can bring to their platforms, and Dynatrace is no stranger to this. Years ago, we saw the value that AI could bring to the application stack, specifically the troubleshooting of an application with true root cause analysis (RCA).
First to note, our AI is not based off an acquisition and bolted on to an existing APM stack. The Dynatrace platform, with AI, was purpose-built from the ground up. That means the AI capabilities within Dynatrace are inherent in all aspects of the platform. This gives us the ability to do more than RCA. This gives us the ability to become a part of the CI/CD pipeline, deployment, and remediation, as well as a part of an orchestration engine.
What the Dynatrace AI does not do is mimic “cognitive” human functions. It does, on the other hand, fall under the definition of “intelligent agents”: any device that perceives its environment and takes actions to maximize its chance of successfully achieving its goals. For Dynatrace, those goals would be a faster time to determine the root cause of an issue of a given application, or group of applications. We do this by using a group of well know statistical models, and years of APM experience. All of this, combined, is what we refer to as the Dynatrace AI. And in all of this, Dynatrace would be considered a deterministic AI.
Statistical Models used in Dynatrace
First, let’s look at the different algorithms & statistical models that we use for our Artificial Intelligence:
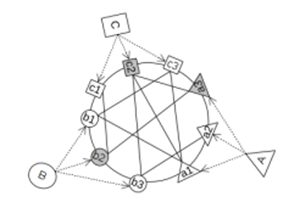
- Graph Ranking Methodology
Used to determine an object’s relevance or importance
Graph ranking uses a random surfer approach to determine the most relevant node within huge graphs of thousands of related components.
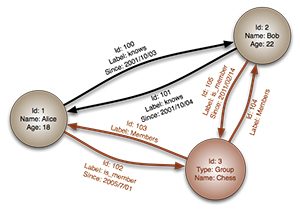
- Graph DB
Used for analyzing complex relationships and interconnections
In computing, a graph database is a database that uses graph structures for semantic queries with nodes, edges, and properties to represent and store data. A key concept of the system is the graph (or edge or relationship), which directly relates data items in the store.
- Multidimensional Baselining
Used to understand how everything behaves
A multidimensional database (MDB) is a type of database that is optimized for data warehouse and online analytical processing (OLAP) applications. Multidimensional databases are frequently created using input from existing relational databases.
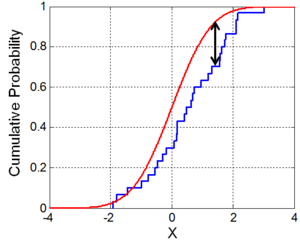
- Kolmogorov–Smirnov
Used for dynamic baselining
In statistics, the Kolmogorov–Smirnov test (K–S test or KS test) is a nonparametric test of the equality of continuous, one-dimensional probability distributions that can be used to compare a sample with a reference probability distribution (one-sample K–S test), or to compare two samples (two-sample K–S test).
- Temporal Correlation
Used to align events over a timeline
A function that gives the statistical correlation between random variables, contingent on the spatial or temporal distance between those variables.
- Holt-Winters Exponential Smoothing
Used to smooth out anomalous behavior, working in conjunction with Kolmogorov-Smirnov
A rule of thumb technique for smoothing time series data, particularly for recursively applying as many as three low-pass filters with exponential window functions. Such techniques have a broad application that is not intended to be strictly accurate or reliable for every situation.
How does Dynatrace use AI?
The Dynatrace AI-powered causation engine pinpoints root causes automatically. To help understand this, let’s first discuss the difference between correlation and causation. An example of correlation would be me driving down the road, hitting a pothole, and the vehicle behind me getting a flat tire. The two events are correlated, but my driving over a pothole did not cause the other vehicles flat tire. Causation would be the other vehicle driving over a nail, and their tire goes flat. The cause of the flat tire was a nail.
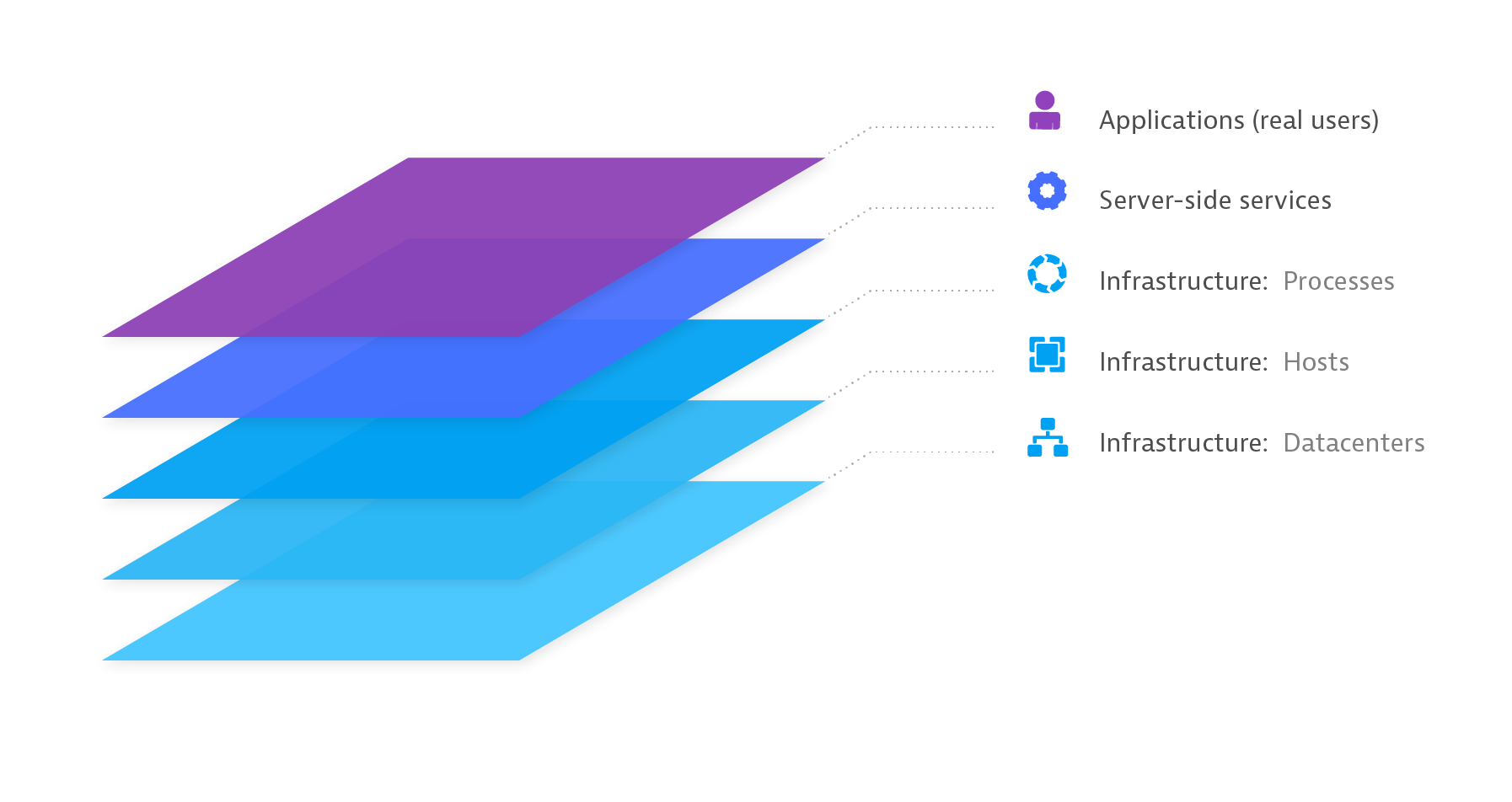
The Dynatrace AI considers all the terabytes of information about what’s going on in your application environment-
- monitoring data in semantic context via unified OneAgent metrics collection and PurePath transaction tracing
- anomalies and threshold violations, as determined by the suite of smart baselining algorithms
- actual dependencies (discovered and mapped out in the real-time Smartscape model)
- baked-in expert knowledge
- sequence of events
-and calculates the probability of individual incidents causing other incidents, applying an eigenvector centrality algorithm (the same ranking approach used by Google Search) to build a weighted graph of all related incidents to determine what issue has the highest statistical probability of being the root cause.
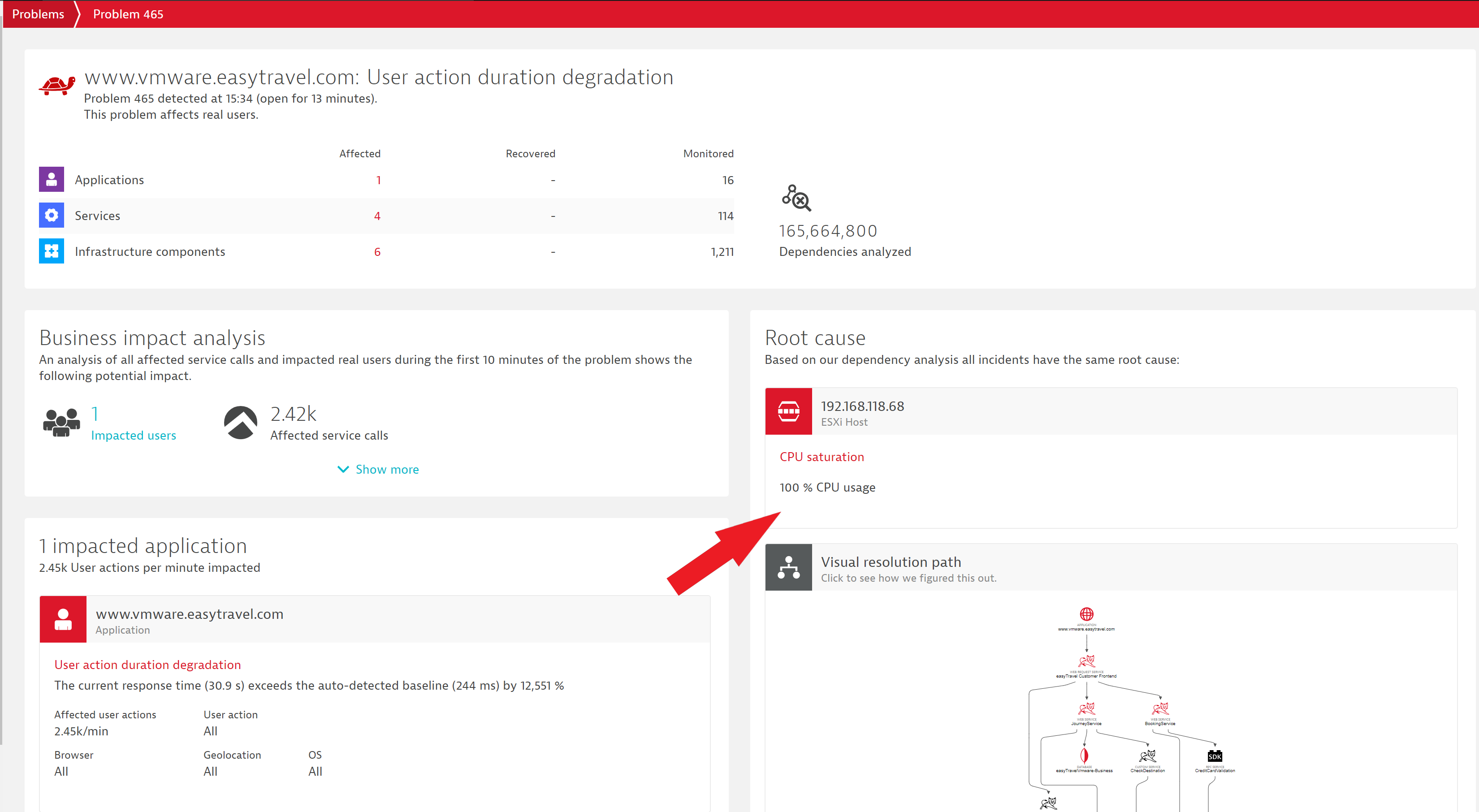
But that’s not all we can do with our AI.
Now imagine using this as part of a development pipeline. In a Shift-Left world, the idea is to perform testing earlier in the lifecycle. With Dynatrace’s auto-baselining, through its statistical modeling and Holt-Winters smoothing, we can identify regression in code releases early. Using APIs we can communicate that regression to external orchestration tools like Ansible Tower or AWS CodeDeploy, triggering management workflows or auto-remediation actions. At the same time, the AI would determine the root cause of the regression, allowing the developers to investigate the problem and quickly determine where changes needed to be made in their code.
There really are very few limitations to how Dynatrace can enhance the way you do business.
Summary
According to Bernard Marr, in a Forbes article, AI is impacting us in our everyday lives and business decisions.

At Dynatrace we’ve come to realize that the traditional monitoring approach of watching dashboards, responding to alerts, and manually analyzing data sets doesn’t work anymore. Today’s hyper-dynamic, highly distributed application environments have become too complex and move too fast. The volume, velocity, and variety of information is simply more than humans can keep up with using traditional tools.
But artificial intelligence can absorb terabytes of data and make sense of it instantaneously. AI automates all the “heavy lifting”. All the discovery and analysis that take teams of experts hours or even days, AI does in milliseconds to proactively identify problems and pinpoint the underlying root cause, and so much more.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum