
Dynatraceダッシュボードはペタバイト規模のオブザーバビリティデータを可視化しますが、その真価を発揮させるには、最も重要な情報に焦点を当てる方法を知ることが不可欠です。本シリーズ第3部では、様々なフィルタリングオプションを活用し、最も関連性の高い情報に絞り込む手法をご紹介します。
Dynatraceダッシュボードでは、データフィルタリングを複数の方法で実施でき、それぞれ異なるユースケースに適しています。本チュートリアル終了時には、以下の操作が可能となります:
- タイル上に直接インスタントアドホックフィルターを適用
- 変数を使用して複数のタイルをまたがってフィルタリングする
- ビジネスコンテキストに沿ったプラットフォーム全体のフィルタリングにセグメントを活用する
Kubernetesリソース使用状況を監視するための既製ダッシュボードを例に、これらの手法を順を追って説明いたします。このダッシュボードはトラブルシューティングとパフォーマンス分析を目的に開発されており、Dynatrace Playgroundでご確認いただけます。
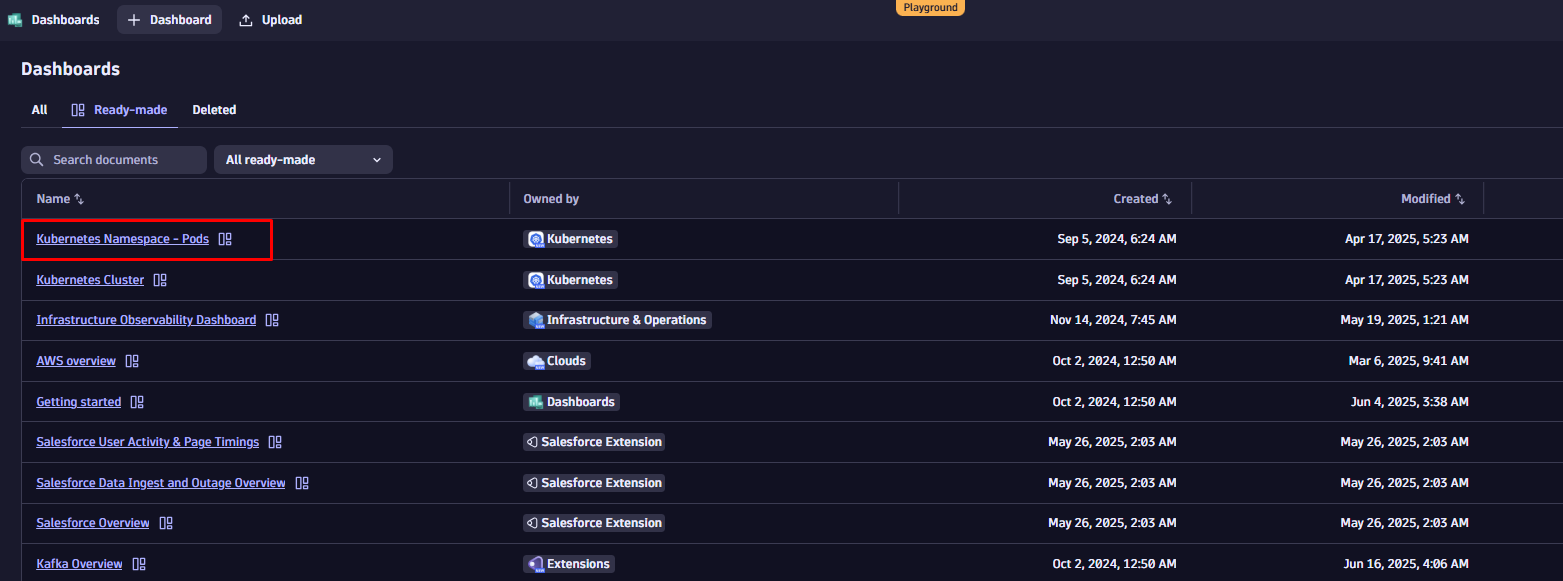
手順に沿って進めるには、まずダッシュボードを複製してください。ダッシュボードリストを開き、「Kubernetes Namespace – Pods」を検索し、ダッシュボード名の横にあるコンテキストメニューから「複製」を選択してください。
迅速かつ集中的に:タイル設定でデータを即座にフィルタリング
まず、各タイルに個別のフィルターを設定する方法をご説明いたします。
パフォーマンス指標に加え、エラーや警告、その他の重要なイベントといった深いコンテキストを提供するログデータを追加することで、Kubernetes ダッシュボードを強化したいと仮定しましょう。この強化により、問題の相関関係を迅速に把握し、トラブルシューティングの効率を向上させることができます。
タイル設定のフィルターフィールドを使用し、表示データを絞り込み、エラーメッセージのみに焦点を当てます。具体的には以下を追加します。
loglevel = ERROR
「実行」をクリックすると、新しいフィルターが適用されます。不要なログレベルを除外したい場合は、フィルター条件を次のように変更することで実現できます:
loglevel != INFO
特定のサービス、メッセージ内容、またはログソースごとにログをフィルタリングすることも可能です。フィルターの適用は、メトリクスやビジネスイベントなど、他のすべてのデータタイルでも同様に機能します。
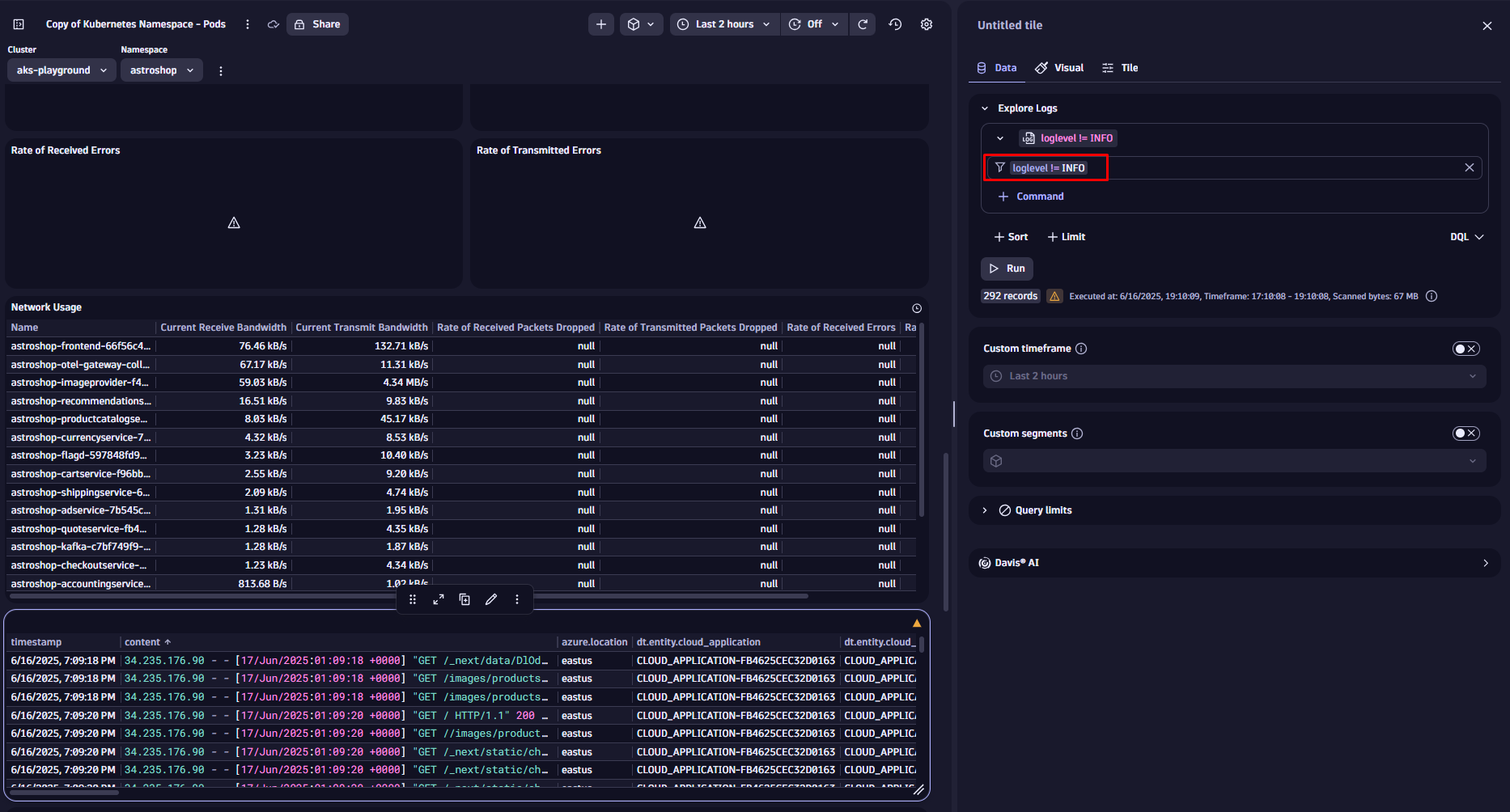
自然言語または DQL を使用してデータをクエリおよびフィルタリング
あるいは、クエリ自体にフィルタ条件を追加してデータをフィルタリングすることもできます。その場合は、Davis CoPilot™ をご利用いただけます。AI によるクエリにCoPilot タイルを追加し、プロンプトの一部として必要なフィルタリングを含めるだけです。
すべてのログを取得し、ログレベルが ERROR に等しいもののみをフィルタリングします。最新の 100 件のログのみを表示します。
Davis CoPilot は、入力内容を Dynatrace Query Language (DQL) に自動的に変換します。生成されたクエリを表示し、フィルタコマンドがどのように適用されているかを確認するには、プロンプトフィールドのすぐ下にあるDQLを選択してください。
さらに詳しく知りたいですか?DQL は非常に強力なフィルタリング機能と、柔軟な代替手段を提供します。例えば、最近導入された検索コマンドは、データ内の特定の情報の保存場所や保存方法がわからない場合に最適です。詳細については、ドキュメントの「DQL クエリの使用方法」のトピックをご覧ください。
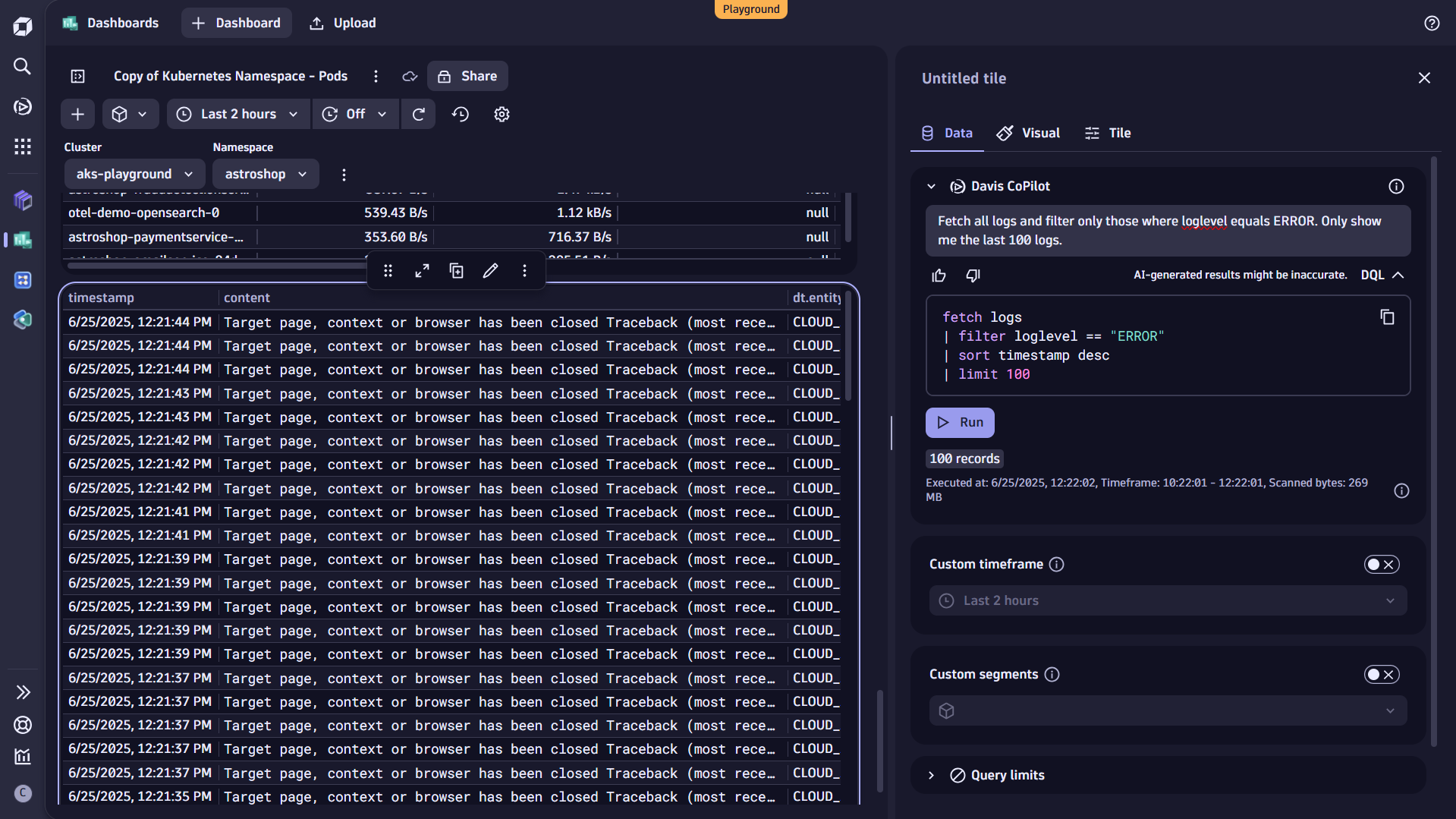
変数を使用した複数タイルにわたる動的フィルタリング
これまで、特定のタイルに静的なフィルターを追加する方法に焦点を当ててきました。変数を使用することで、ダッシュボードをインタラクティブにし、複数のタイルにリアルタイムでフィルターを適用することが容易になります。
例えば、複数のKubernetesネームスペース間でリソース使用量を比較する場合、手動で行うと毎回各タイルのネームスペースを変更する必要があります。これは時間がかかり、ミスも発生しやすくなります。変数を使用すれば、単一の入力からタイルをフィルタリングできるため、この問題を解決できます。
変数の定義はシンプルで直感的です。最も簡単な方法は、静的変数から始めることです。ここでは、自由形式のテキストとして項目リストを手動で追加します。リストの入力としてCSVファイルを使用することも可能です。
さらに、動的変数も利用可能です。これは、Grailに保存されているデータや外部から取得したデータに基づいてエントリを生成します。このアプローチの利点は、値が変更された場合でも、変数が常に自動的に更新される点にあります。
当社のサンプルダッシュボードでは、クラスターやネームスペースなどの変数が既に用意されています。右上のオーバーフローメニューをクリックすると、既存の変数の表示・編集や新規変数の追加が可能です。
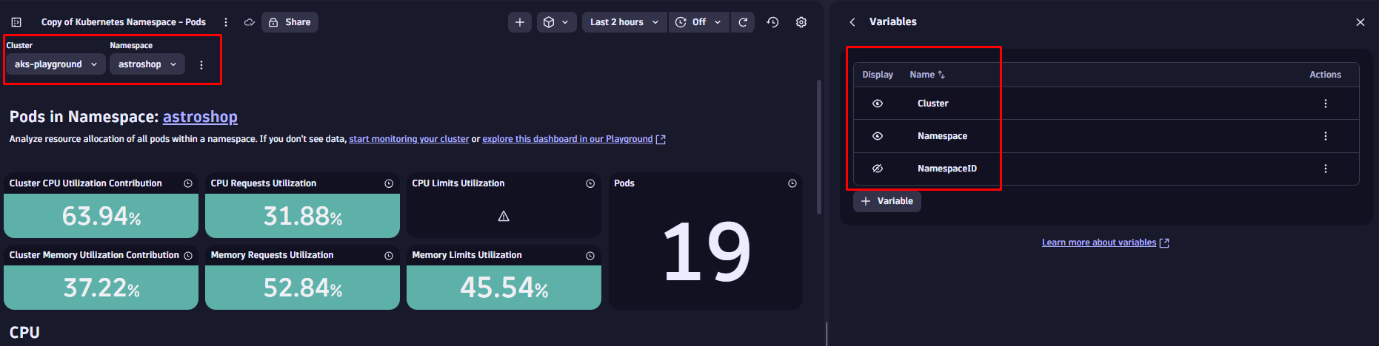
また、非表示変数も使用できます。これはドロップダウンには表示されませんが、特定のタイルを駆動するためにバックグラウンドで使用され、ダッシュボードを整理して焦点の合った状態に保ちます。
タイルへの変数の追加
まず、ログタイルのフィルター式を強化するため、変数を追加してみましょう。これは静的値を使用するのと似ていますが、今回は$記号とその後に変数名を続けて既存の変数を参照します。フィルターを更新し、クラスタ名とネームスペースを追加しましょう。
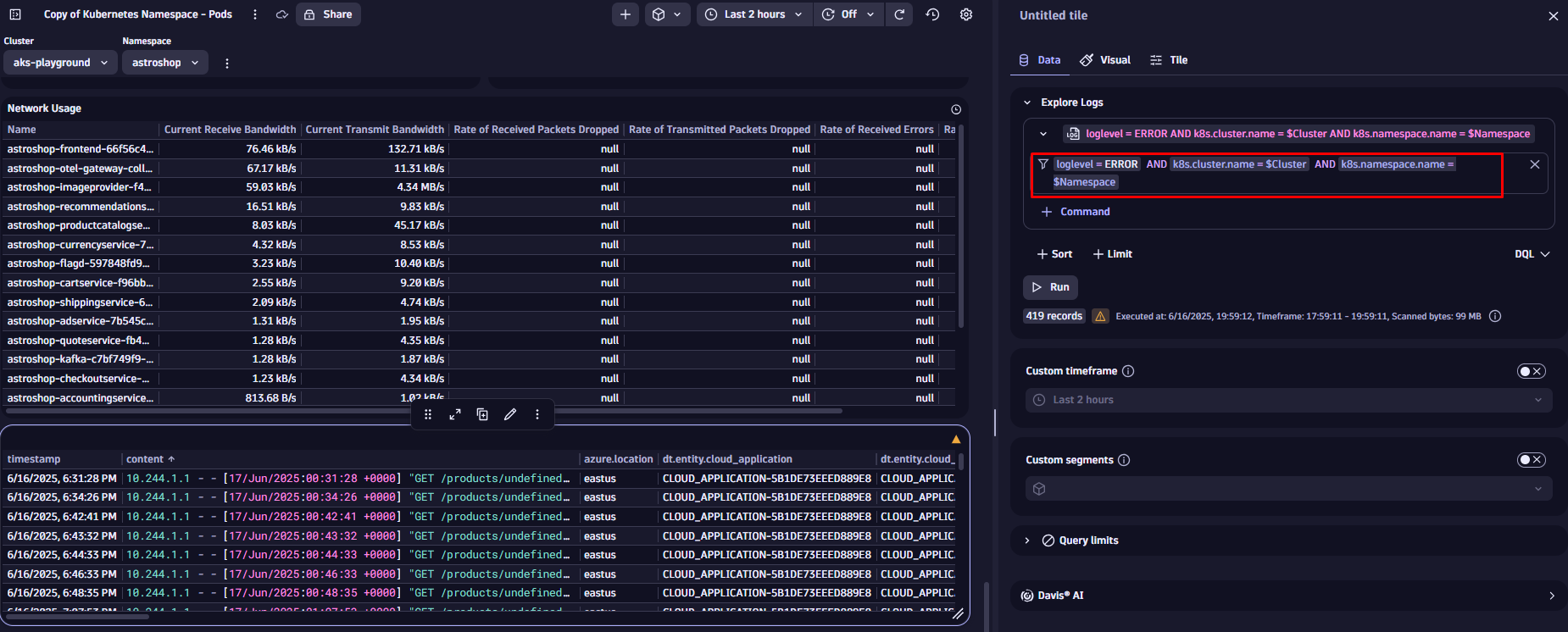
保存後、ダッシュボード上部のドロップダウンを使用して、先ほど更新したログタイルのデータをフィルタリングできます。変数はすべてのタイルでサポートされています。詳細については、ドキュメントの「ダッシュボードに変数を追加する」トピックをご覧ください。
セグメントを使用してビジネスコンテキストに沿ったフィルターを作成する
セグメントは、Dynatrace 内のデータを論理的に構造化するために使用されます。動的で多次元的なセグメントは、データを簡単に切り分け、アプリ間でフィルタリングを永続化する方法を提供します。組織単位、ハイパースケーラーのリージョン、インフラストラクチャコンポーネントなど、現実世界のディメンションに基づいて、特定のユーザーの(ビジネス)コンテキストを追加する方法を導入します。
本例では、テナントに既に定義済みのセグメントを使用します。ダッシュボード右上の四角アイコンを選択すると、セグメントを選択できます。
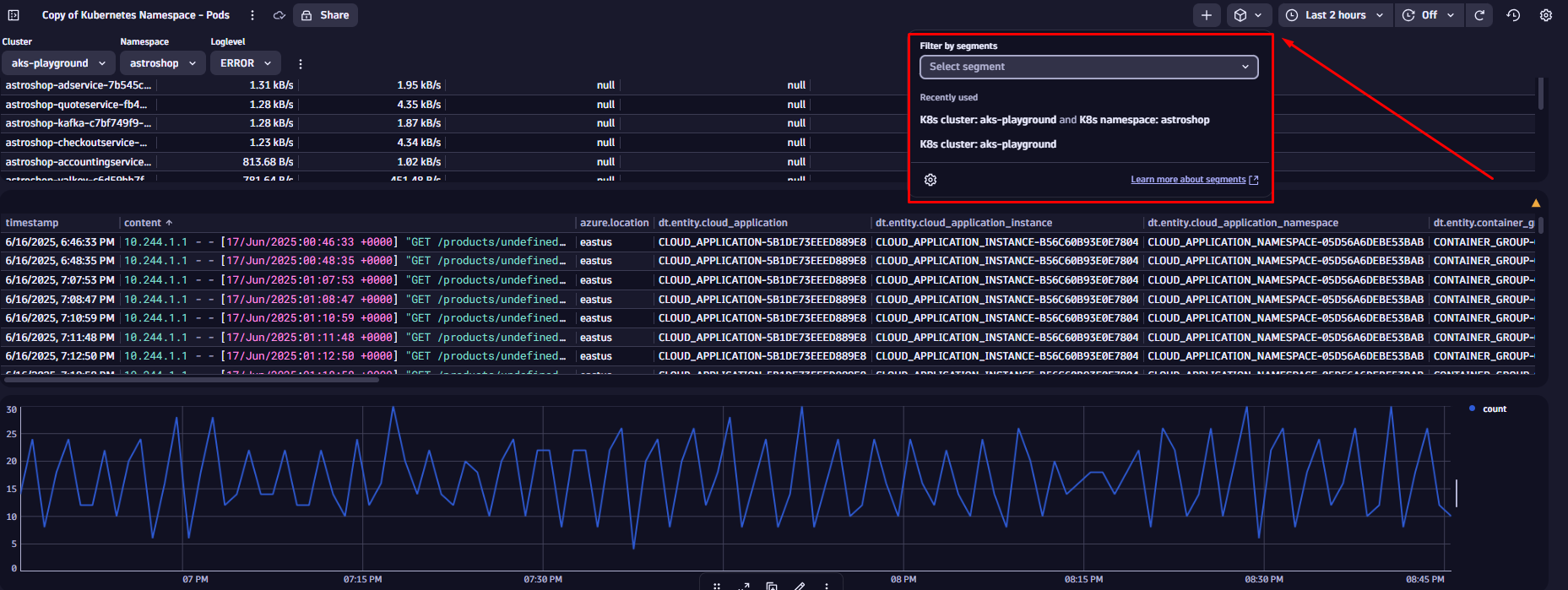
「K8sクラスター」および「K8sネームスペース」セグメントを適用してみましょう。K8sクラスターセグメント(例:aks-playground)を選択すると、変数を使用して監視対象のKubernetesクラスターを動的に一覧表示します。また、選択したクラスターに関連する全データを自動的に取得する事前定義条件も含まれています。
ご注意ください:セグメントを適用するたびに、データ全体に対して事前フィルタとして機能します。可視化されたクエリ条件として表示されることはありませんが、ダッシュボード上で最初のフィルターとして適用されます。
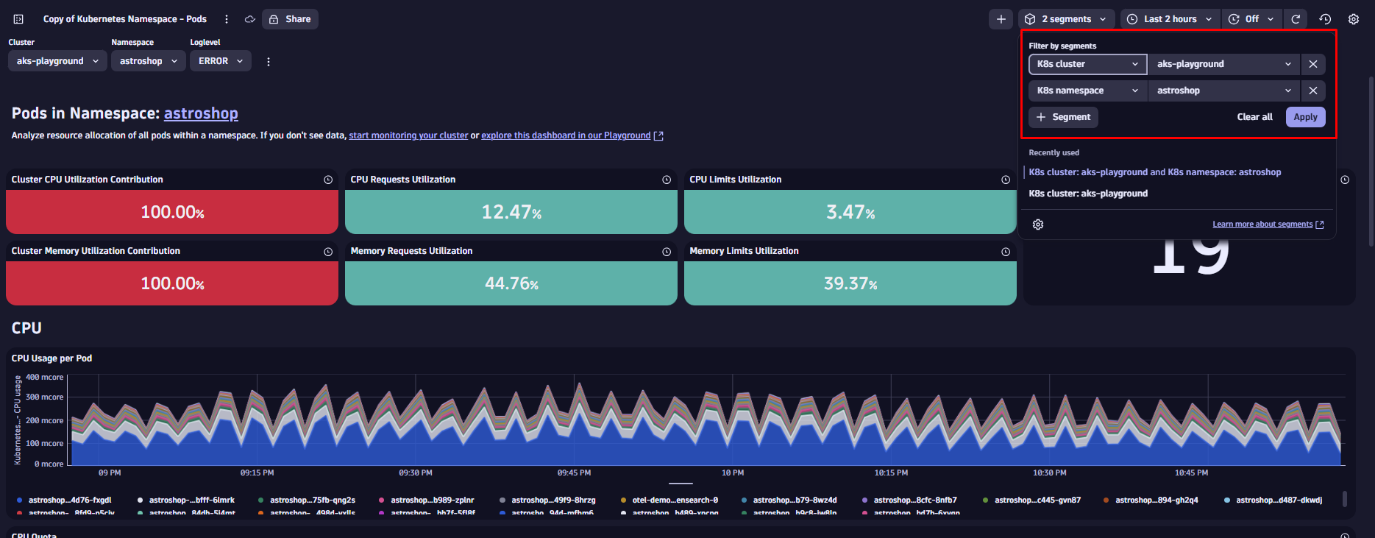
セグメントは多次元的なため、重ねてより精密なフィルタリングが可能です。K8s ネームスペースセグメント(例:astroshop)を積み重ねると、対象範囲がさらに絞り込まれます。ダッシュボードのタイルは、手動での更新を必要とせず、そのネームスペースに関連するデータのみを即座に反映します。
選択したセグメントに基づいてデータが事前にフィルタリングされるため、このアプローチはパフォーマンスを向上させ、処理されるデータ量を削減します。これは特に大規模な環境において有用です。
独自のセグメント構築方法については、Kubernetes セグメントチュートリアルをご覧ください。
Dynatrace ダッシュボードと変数の実際の動作をご覧ください
これまで、Dynatrace ダッシュボード内でデータをさまざまな方法で分析する方法をご紹介しました。別の例をご覧になりたい場合は、Andreas Grabner によるこのオブザーバビリティラボ動画をご覧ください。実践的なユースケースを解説しています:


ご質問がおありですか?
Q&Aフォーラムで新しいディスカッションを開始するか、ご支援をお求めください。
フォーラムへ移動