
Although containerizing applications is not a new concept, it was recently rejuvenated by Docker and has taken the IT world by storm. In this post we present a way Docker containers were used in conjunction with Ansible to automate and generalize the use of Dynatrace monitoring at a major telecommunication company in APAC.
Tools of choice: Docker, Ansible and Bamboo

Docker is a vast subject and goes beyond the scope of this post but it is, in a nutshell, an all-in-one software package aimed at building and running containerized applications. Containers are portable and many copies can be deployed very quickly, making it ideal for certain workloads such as Tier 1 and Tier 2 Java applications. They are also self contained which means that they feature all that is required for an application to run. If this were not the case, it would break portability! Docker containers can be run on full-blown Linux installs or on more nimble operating systems such as CoreOS. Call it a premonition, but something actually tells me that containers and minimal OS images will probably power the web of tomorrow.
Ansible is an alternative to tools such as Puppet or Chef. It has some interesting specificities compared to its illustrious competition: it is agent less, uses ssh connections, and combines configuration management with orchestration. Its yaml-based syntax makes it easy to apprehend and run, which can’t be said of other configuration management tools whose DSL can be hard to learn. All of this has made Ansible a very good match for Docker based infrastructures.
Bamboo is Atlassian’s CI/CD tool and was used in this project for a number of things: creating rpm packages for all Dynatrace components, building Docker images and deploying those images by executing Ansible playbooks and/or scripts.
Dynatrace in an Infrastructure-as-Code world
Entrusted with the task of making Dynatrace one of the standard monitoring tools for an new, “up-to-date”, scalable, elastic, automated CentOS 6 based web-hosting platform, I had three layers to integrate and hopefully automate: the application layer with Dynatrace agents, the Dynatrace collector layer and the Dynatrace server layer. I had also to integrate with the technology choices made by the team building this new platform: Docker and Ansible were chosen as basic building blocks to deploy and run Java-based applications.
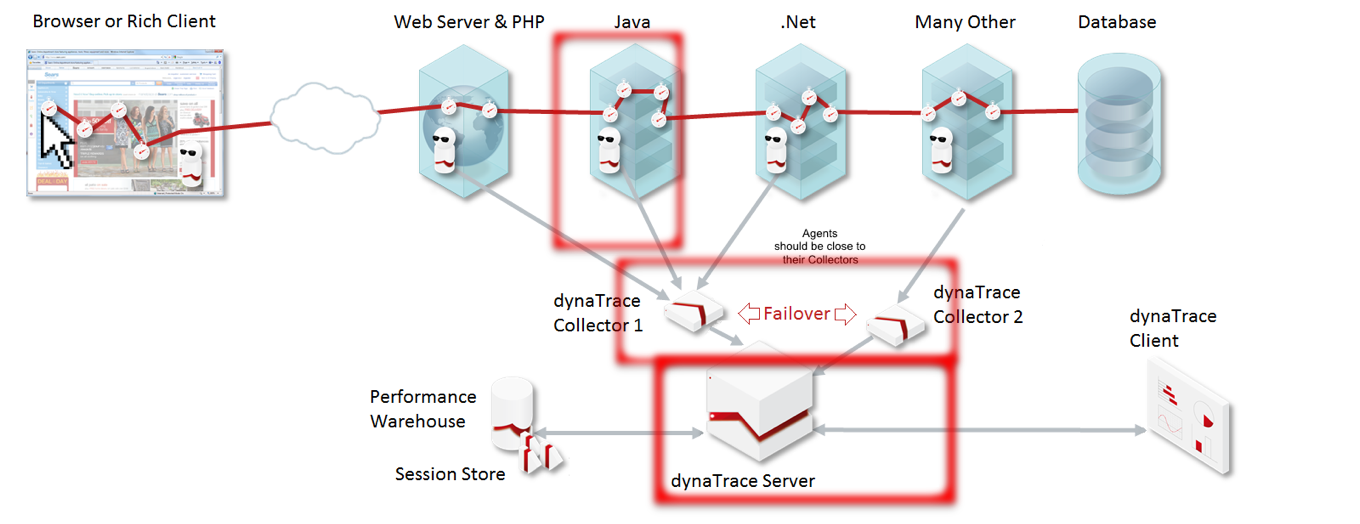
I will describe here the strategies chosen for automating the deployment of the different Dynatrace layers.
Automated Deployments of OneAgents
One of Bamboo’s roles in our environment is to run Maven builds to create Linux rpm packages for all our software, including Dynatrace. As such, the Dynatrace agent which comes as a jar installation file is repackaged as an rpm. This makes installing/uninstalling easy and integrates with internal software repositories for CentOS.

One of the cool things about Docker is that there is an “inheritance” system for containers. What it means is that you can have a generic Tomcat 7 container for instance, and then each application inherits that container and adds to it. Therefore, the logical place of choice to have the Dynatrace agent is in the parent Tomcat container (or parent Jboss container, etc.). Any child container will inherit the agent: no more deployment of agent application by application! The Dynatrace agent is installed in the container via this line in the Dockerfile (see the official documentation for more information on Dockerfiles):
Another critical component of automation is the ability for the agent to “self configure” i.e. to determine its name based on the environment. This is where DNS is your friend. In our environment, a simple DNS call fetches all this information, which can in turn be used to configure the agent name:
$ dig -x 10.1.1.51 TXT +short
NODE_UUID=XXXX-XX-XXXX-XXXXX NODE_DATACENTRE=xxx NODE_ENVIRONMENT=application3 NODE_ENVIRONMENT_TYPE=production NODE_PLATFORM=PLATFORM_NAME NODE_SERVICE=application-tier1 NODE_SHORTNAME=vm001 NODE_TIER=presentation
A Dynatrace environment shell script running at application startup time can easily get this information and configure the agent name as such:
$ export JAVA_OPTS="-agentpath:${DYNATRACE_BINARY}=name=${NODE_SERVICE}-${NODE_ENVIRONMENT},server=${DYNATRACE_SERVER},overridehostname=${HOST_NAME} $JAVA_OPTS"
Dynatrace Collectors
On our platform, all applications run in Docker containers, and the Dynatrace collectors are no different. It is an easy piece of software to “dockerize” as it consists of one JVM and does not require any local storage. It is handy to be able to quickly deploy more collectors to handle more traffic (scaling up).
As with any other application, Dynatrace collectors deployments are initiated by Bamboo which itself runs an Ansible deployment playbook. Environment variables can be passed on the containers to customise some of the features.
For instance, a DYNATRACE_SERVER environment variable configures the collector running inside the container to point to a particular Dynatrace server. This allows for multiple servers and sets of collectors to co-exist.
Dynatrace Server
The Dynatrace server is an interesting problem in terms of automation: it requires a database (the Performance Warehouse) and has some stringent licensing requirements.
I have tried three different approaches:
- Full “dockerization” of the Dynatrace server and its database (both in separate containers)
- Using Packer (https://packer.io/) to produce a VM image with all the software already configured
- An Ansible playbook that deploys a Dynatrace server as well as a database on a ‘blank’ VM
The full dockerization of the server posed interesting issues with regard to licensing, as Dynatrace licenses are dependent on the mac address of the first network interface as well as the hostname. Both of those things could be made constant but this goes against the philosophy of containerization. Also, as I did not expect to have to deploy that many Dynatrace servers that often, containerization did not offer a distinct advantage. As the platform matured, it was decided that all VMs across the board would be immutable i.e. would stem from the same image. Therefore, also the packer option was abandoned.
This left the Ansible playbook option which worked extremely well. Since the inception of the platform Dynatrace jumped from version 5.6 to 6.2, with the latter offering more automation options through the REST API. In particular, it is now possible to configure the Performance Data Warehouse through REST calls, which wasn’t possible with version 5.6. This meant that a few manual steps were needed such as configuring the Performance Data Warehouse and changing the admin password. The Performance Data Warehouse (Postgresql) runs on the same VM as the Dynatrace server and is deployed by the same Ansible playbook, taking advantage of the built-in postgres modules.
Although unrelated to the code I wrote, note that Dynatrace has produced freely available Ansible playbooks and also integrates with other vendors to manage and deploy their products.
Benefits
The different strategies mentioned above bring benefits at every layer of the Dynatrace infrastructure:
- Embedding Dynatrace agents in parent containers for applications is a huge time saver as no manual operation is required for new applications, it’s already done!
- Dockerizing collectors allow for quick scaling of the number of collectors which caters for increase in traffic.
- Finally, having an Ansible playbook which can deploy a server and its Performance Data Warehouse in a matter of minutes makes it easy to create new infrastructures in test. It is also integrated in the restore procedure for a server, combined with a full backup of the Dynatrace configuration and the Performance Data Warehouse.
Dynatrace in the DevOps Process
A monitoring solution providing continuous feedback is an integral part of a DevOps strategy, alongside CI/CD and automation. Without proper monitoring it is hard to gauge the value of potential improvements — whether for business or performance — to applications or the underlying infrastructure. Additionally, Dynatrace gives Operations and Development a common referential to discuss potential issues and resolve incidents. I can attest that this is what I experienced with this work.
I am looking forward to implementing Dynatrace in an automated testing capability, using the same tool to assess performance in production, and as part of the integration process is rapidly becoming a must.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum