
Some vendors use time based correlation to connect events across multiple observed data sets and claim there’s a connection between two observed data sets. This type of approach is flawed and can lead to wildly inaccurate conclusions, which itself leads to wasted time by technical teams and high cost to the business.
In the chart below we observe the Number of Requests and the Memory Utilization. Wow, the increase in the Number of Requests is causing memory utilized to go up. Quick, call Engineering and get them on this right away.
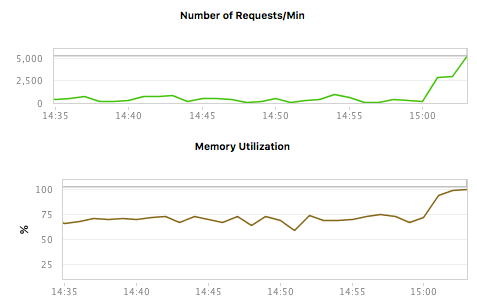
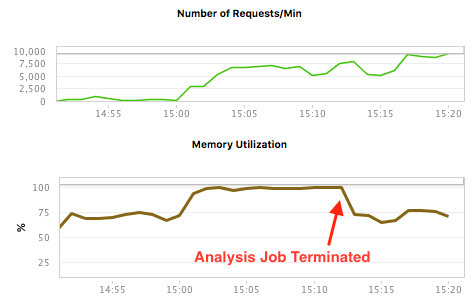
We can easily see that there’s a correlation between the Number of requests and the memory size. Based on this data it would be relatively easy to conclude that the increase in Requests is causing memory to increase. But the truth is simply that these two observed values have nothing to do with each other. After talking to the system operators, we learn that a large memory intensive analysis job was running. Once they shut down the Analysis job, things changed. Look at the same measures after a few minutes have passed. Same conclusion? Probably not.
A far superior approach is to use causation, instead of a correlation. A causative based approach would provide us 100% confidence about whether an observed data point does cause another observed data point.
So why doesn’t everyone use Causation? Partly because truly using causation is harder to implement in an APM product and many customers don’t understand the difference. Let’s look at what these terms mean and why they’re similar but distinctly and so importantly different.
Correlation & Causation
Studies show (ok, not really, I just made this up) that when I sleep more I make more money. The assumption is sleeping causes one to make money. But I’m sure most of us realize that sleeping more is likely letting me be more awake during the day, being a more productive worker and thus producing more outcome which leads to higher income. But if I took the connection between sleep and income directly, I would conclude I should just sleep 24/7 and make lots of money. As we all know, the sleep itself isn’t directly generating the income, but it’s related in some manner. So, we can say that there’s a correlation between sleep quantity and income capacity.
Statisticians measure the relationship between two events and assign a value called the Correlation Coefficient. This is the statistical measure of the degree to which changes to one observed value predict changes to another observed value. Think sleep and income as we discussed earlier. The Correlation Coefficient is defined as a value between -1 and +1. There can also be negative correlation. For example, in the winter, the longer my wife leaves the front door open to talk to the neighbor the colder the house gets. So, there’s a negative correlation between the door open time and the house temperature. In contrast, every time I turn the stereo volume knob to the right, the volume increases, a positive correlation.
The Correlation Coefficient simply measures the strength of the association between two values or events. If I see a direct pattern of one value changing in sync when another value changes, then I can assign a high coefficient of correlation. But that is still not causation. Why is it so important to have causation? Let’s look at another example of what happens when correlation is used incorrectly.
Incorrect Conclusions
Just because we observe one value as going up and observe another value go up, does not mean they have anything to do with each other. The Number of Requests and Memory example above is a good example, and understandably confusing. Let’s look at a more obvious example. Tyler Vigen[1] did some great work using US Census data to look for spurious correlations in random public data and came up with some great conclusions. Did you know that margarine consumption can cause divorce?[2]
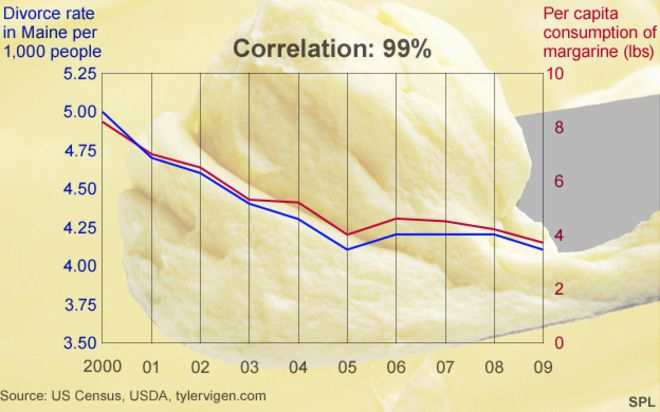
Clearly there’s no connection between margarine consumption and divorce rates but this is the exact conclusion that some APM vendors make when they use correlation to determine what’s wrong with your Enterprise Data Center.
A better way
There’s lots of products on the market which use correlation but claim confidence in the conclusions like its causation. The APM Market is no exception. We’ve probably all heard the statement “correlation does not imply causation”. It’s not uncommon for products to claim a relationship between two observables simply because they happened at the same time. The Request/Memory and the Divorce/Margarine stories are good examples. Multi-threaded computing systems are another example of where time based correlation can be dangerous and lead to very wrong conclusions.
But what if I was measuring the environment in a way that allowed me to directly connect event A with event B, not because their timestamps lined up, but because when A happened it created a unique identifier which only showed up in things (such as B) which it directly affected and not in C which it did not affect. This gives me 100% confidence that A caused B. Event A did trigger event B and not event C, even though the time stamps all line up together. This is called causation.
Why does this all matter
In complex multi-threaded computing systems, there’s lots of things going on at once. And as a Performance Engineer if I’m going to get to the root cause of my system problems and fix the user response time complaints, I must have an ability to know for certain which events cause what other events particularly as transactions cross threads, processes, machines and even data centers. This allows for quickly resolving issues and accurately getting to the root cause even in complex systems. The following diagram shows a relatively simply transaction that flowed across two java tiers and an Oracle database. This transaction is from a single user click which was reported to be taking too long, 16.2 seconds to be exact (light blue arrow). By using a causation-based approach to analyze the various events in this multi-tier environment, we can easily see that there’s 235 calls into Oracle (see the red arrow), all for a single user click. Note that this makes up 73% of the total users’ response time (green arrow). This type of analysis cannot be done without causation and being able to determine exactly what behavior on a backend database tier is directly the result of a user action on the user’s browser.

If I attempt to use correlation to resolve this type of problem, I would not find this type of problem at all. I would simply be guessing as to what activity on the downstream tiers was caused by the upstream user click event. But only when being able to use causation can I determine what events (trips to the database) are happening as part of a single user click event.
Have confidence and don’t risk your business’s future
The Dynatrace approach of uniquely tagging every remoting call gives the performance engineer causation based data, which gives them confidence and hard facts on what is causing system problems. Being able to point the Dev team directly to the root cause is priceless when time, money and your business reputation is on the line. So why gamble your business with correlation, when you can have the best, causation.
[1] http://www.tylervigen.com/spurious-correlations
[2] http://www.bbc.com/news/magazine-27537142




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum