Tags versus metadata
Dynatrace differentiates between tags and metadata. Metadata properties are key/value pairs that are inherent to any monitored entity. Tags in Dynatrace are labels or markers that do not belong to an entity. Tags however may also have a key/value structure. For example, you can define a tag with key SecurityIsolationLevel that has a different value for different entities. Once a tag and its rules are defined, Dynatrace will apply the tags to new entities automatically.
How are tags and metadata created
Metadata is detected during startup or discovery of a monitored entity and is immutable from within Dynatrace. Metadata is shown in the Properties section of any entity (see the image below).
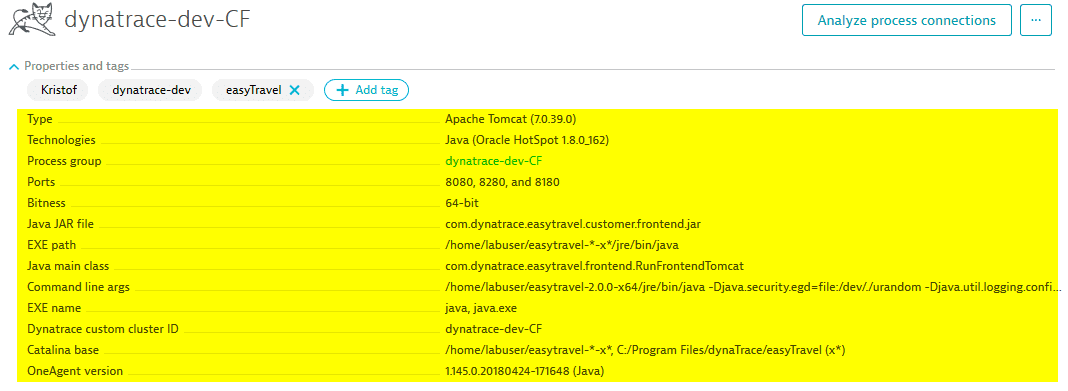
For processes, all metadata is discovered during startup of each process. Metadata is typically not refreshed until a process is restarted. Metadata is considered part of the deployed application or deployed entity and is discovered and/or configured as part of that deployed application. Metadata can't be changed using the Dynatrace web UI.
Tags, on the other hand, aren't information about an entity and don't belong to one specific entity. Tags are used to find/filter/designate sets of entities. Tags in Dynatrace can be changed without changing the deployment itself. They are configurable from within the Dynatrace web UI.
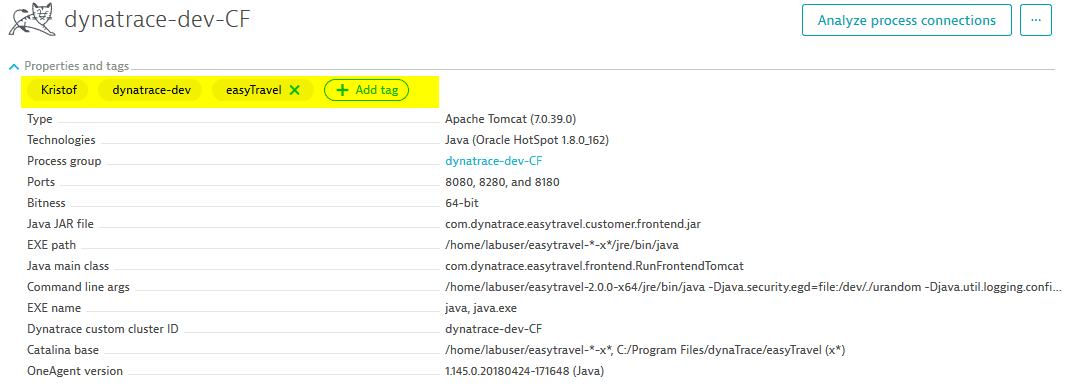
There are several ways to create tags for monitored entities. The best option for you depends on your environment and your needs. The easiest way is to use the Dynatrace web UI to manually apply tags to your entities. However, the manual approach forces you to manually tag each new entity. This maintenance challenge makes it difficult to enforce a standard and is impractical within larger environments. Therefore, within larger environments, it's recommended that you use a combination of auto-tagging based on metadata and tags that are part of the monitored deployment. Through this approach, tags can be dynamically assigned within Dynatrace, based on immutable metadata that come from the monitored system.
With this in mind, note that a Name or a Version is not a tag in Dynatrace. Rather, these are regarded as metadata. An example for tags would be one called Production and another called Staging. A deployment designation like blue/green is metadata but might often make sense as a tag—it's not intrinsic information but rather is used to look at either the blue or the green set of applications.
Importing tags/metadata from external sources
Dynatrace not only discovers all processes running on a host, it also identifies their nature. As part of this, Dynatrace captures the most important domain-specific metadata. If Dynatrace discovers, for example, an Oracle WebLogic entity, the entity will also have metadata about the WebLogic Domain, the WebLogic Server name and the WebLogic Cluster. If Dynatrace identifies a Kubernetes environment, then every process will have metadata concerning its pod name and namespace. The same is true for VMware and AWS hosts.
Dynatrace only knows about a subset of domain-specific information. This is why we also enable you to enrich this information with your own metadata as well as with additional metadata from other sources. In particular:
- Kubernetes and OpenShift annotations are automatically reflected as metadata on processes and process groups in Dynatrace.
- You can use system environment variables to define your own metadata on any kind of process.
Dynatrace adds custom metadata for hosts as well.
Dynatrace adds custom metadata for Cloud Foundry.
This metadata is shown in the properties of each entity within the Dynatrace UI and it's part of the data when you access these entities via the API.
You may also have existing tags in 3rd-party systems that you rely on and that you want to ensure are the same across your organization in an automated fashion. Dynatrace recommends providing such tags via the different means at the time of deployment (Kubernetes annotations, Cloud Foundry tags, AWS tags, environment variables) or set up an integration to send them via the Dynatrace API. These tags will be “read only” in Dynatrace and therefore you won't be able to configure them via the UI.
Where to use tags and metadata
Tags involve a wide spectrum of usages, but in principle they are used to find certain types of entities or to filter views and actions for certain entities. As tags have predominantly an organizational and management purpose within Dynatrace, they are useful for:
Filtering lists
- Defining which entities you want to include in a Data Explorer chart or for dashboard filtering.
- Specifying where to send problem notification based on problem context in problem alerting profiles.
- Defining custom alerts.
- Accessing metric data via the REST API.
Finding and inspecting monitoring results via Dynatrace search.
- Defining a maintenance window.
As mentioned above, tags can have a key/value structure as well. Therefore, you can define, for example, a tag User and assign username as a value dynamically. You can do the same for email, owner and many other properties. However, you will rarely use such key/value pairs for the purposes described above. This would also clutter the Dynatrace UI. Tags are meant for organization, not for defining extra information for your entities. It is therefore important to consider whether something is really a tag (a label or marker) or simply metadata and additional information. When you're in doubt, we recommend that you create metadata, as you can always use the Dynatrace tagging engine to create a tag based on metadata and assign the value dynamically. You can find further guidance in Best practices and recommendations for tagging.
You can use metadata to
- Apply tags to entities via rules.
- Apply naming schemes to your process groups and services.
- Define Management zones.