Adjust the sensitivity of anomaly detection
Some typical anomalies detected by Dynatrace include failure rate increases, response time degradations, and spikes or drops in application traffic. By observing your environment, Dynatrace learns reference values representing its normal behavior and adapts anomaly detection accordingly. This process is called automatic baselining. Apart from using the automatic baseline, you can provide fixed thresholds that define when to raise a problem and alert. You can set these configurations globally or for specific entities.
The sensitivity of problem detection controls the level of statistical confidence required to raise an alert.
| Sensitivity | Statistical confidence | Notes |
|---|---|---|
| Low | High | Useful in development and pre-production stages, avoiding too many alerts. |
| High | Low | A problem is raised even if just a few data points have violated the threshold. Useful for mission-critical production services. |
For some criteria, Dynatrace distinguishes between absolute and relative thresholds. In the example below (it shows a part of anomaly detection configuration for application) the thresholds for key performance metric degradation are set to 100 ms (absolute) and 50% (relative) above the auto-learned baseline. The threshold for the slowest 10% of the requests is set to 1,000 ms (absolute) and 100% (relative) above the auto-learned baseline.
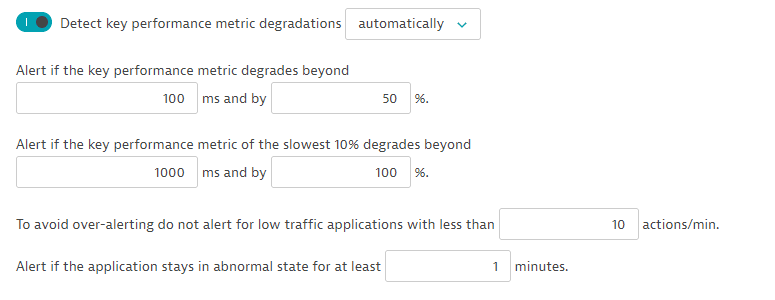
Additionally the anomaly detection considers the number of actions per minute that have to happen in the monitored application (10 actions per minute in the example above). With that setting you can disable alerting for low traffic applications and services—baselining and alerting on low traffic applications often leads to unnecessary alerts.
To configure detection sensitivity on the global level
- Go to Settings.
- Expand Anomaly detection.
Select the required entity type. For specific instructions, see one of the topics below.