

Synthetic monitoring
Automatically monitor and test application availability and performance across production and development environments so you can fix issues and optimize digital experience before users are affected.
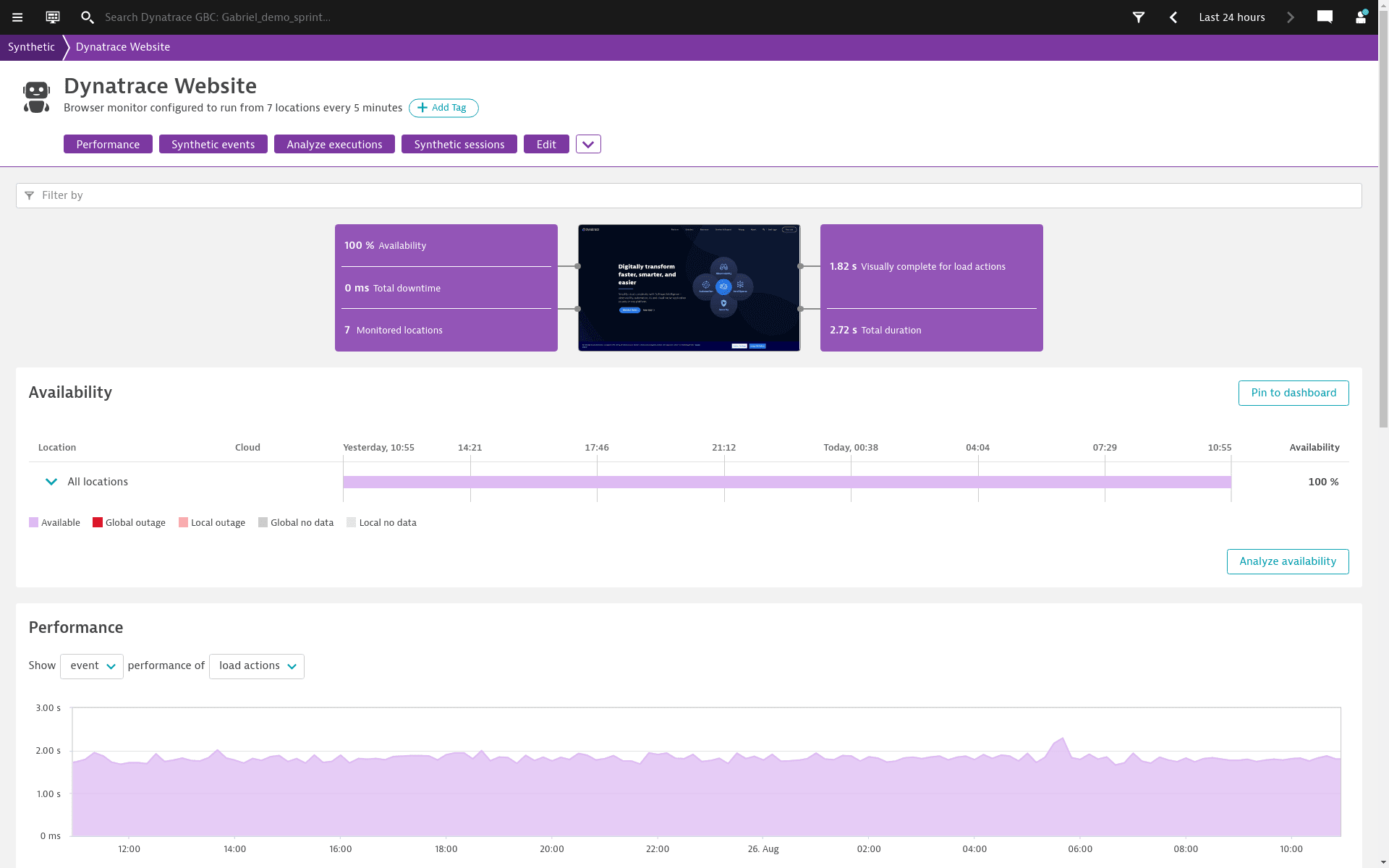
What is Synthetic Monitoring?
Synthetic monitoring is an application performance monitoring practice which emulates the paths users might take when engaging with an application. Synthetic monitoring can automatically keep tabs on application uptime and tell you how your application responds to typical user behavior, and it uses scripts to generate simulated user behavior for various scenarios, geographic locations, device types, and other variables. Once this data has been collected and analyzed, a synthetic monitoring solution can give you crucial insights into how well your app is performing.
Proactively find incidents before they affect users
Test, measure, and compare your mobile and web channels from thousands of locations around the world to emulate real user behavior, meet your SLAs, and manage CDN and third-party performance.
- Leverage a best-in-class network with low latency, high throughput, and high redundancy
- Simulate customer journeys across all major desktop and mobile browsers
- Ensure your key pages, APIs, and transactions continuously perform properly from all locations
- Execute monitors from private locations to track the availability and performance of your internal resources
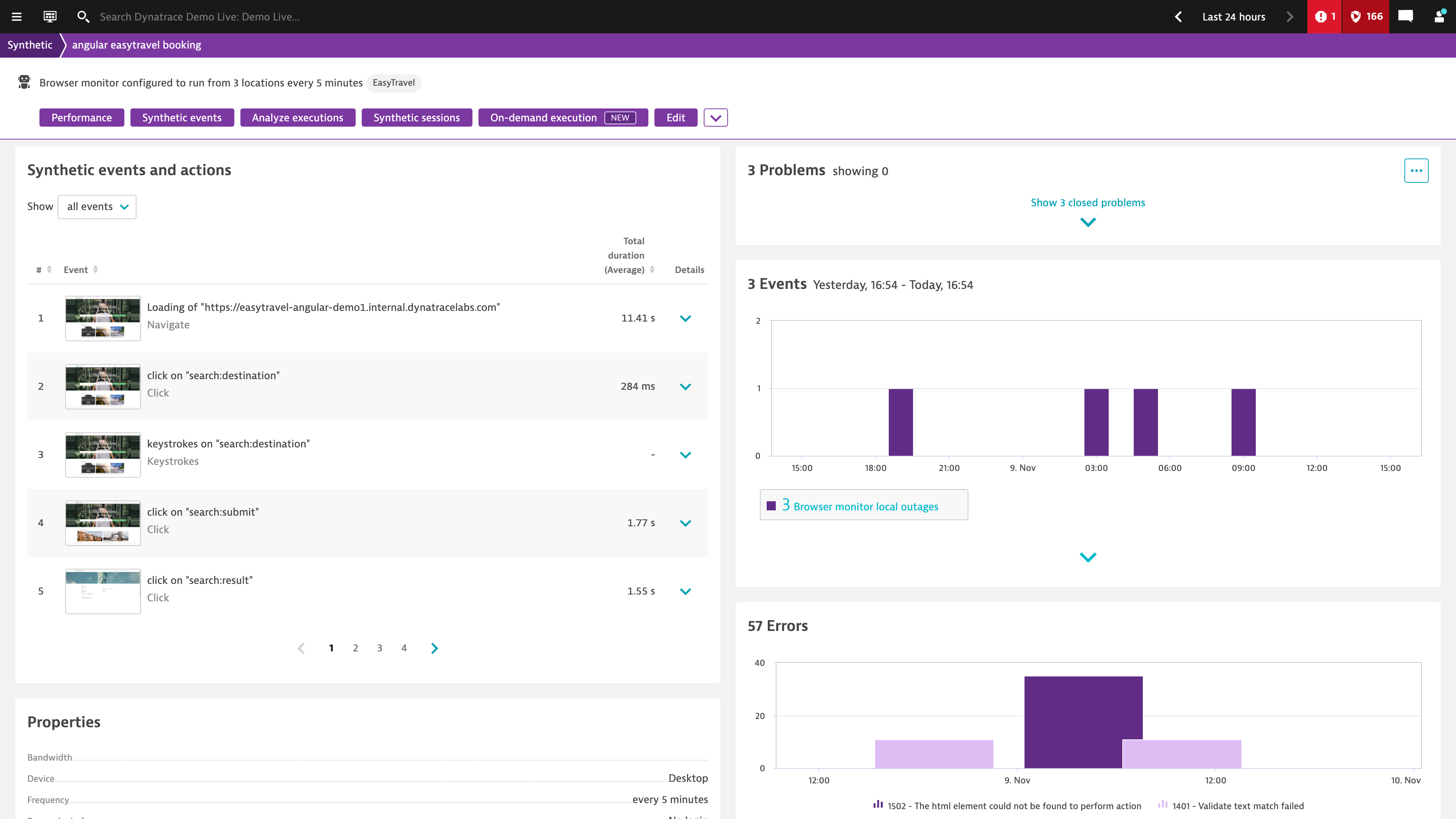
Simulate business-critical customer journeys
Use our unique web-based recorder to easily click through and record the business-critical transactions most important to your business and customers.
- Monitor critical workflows without scripting, using a simple web-based recorder
- Play back scripted transactions to ensure your tests are accurate
- Test business transactions and run them from real browsers
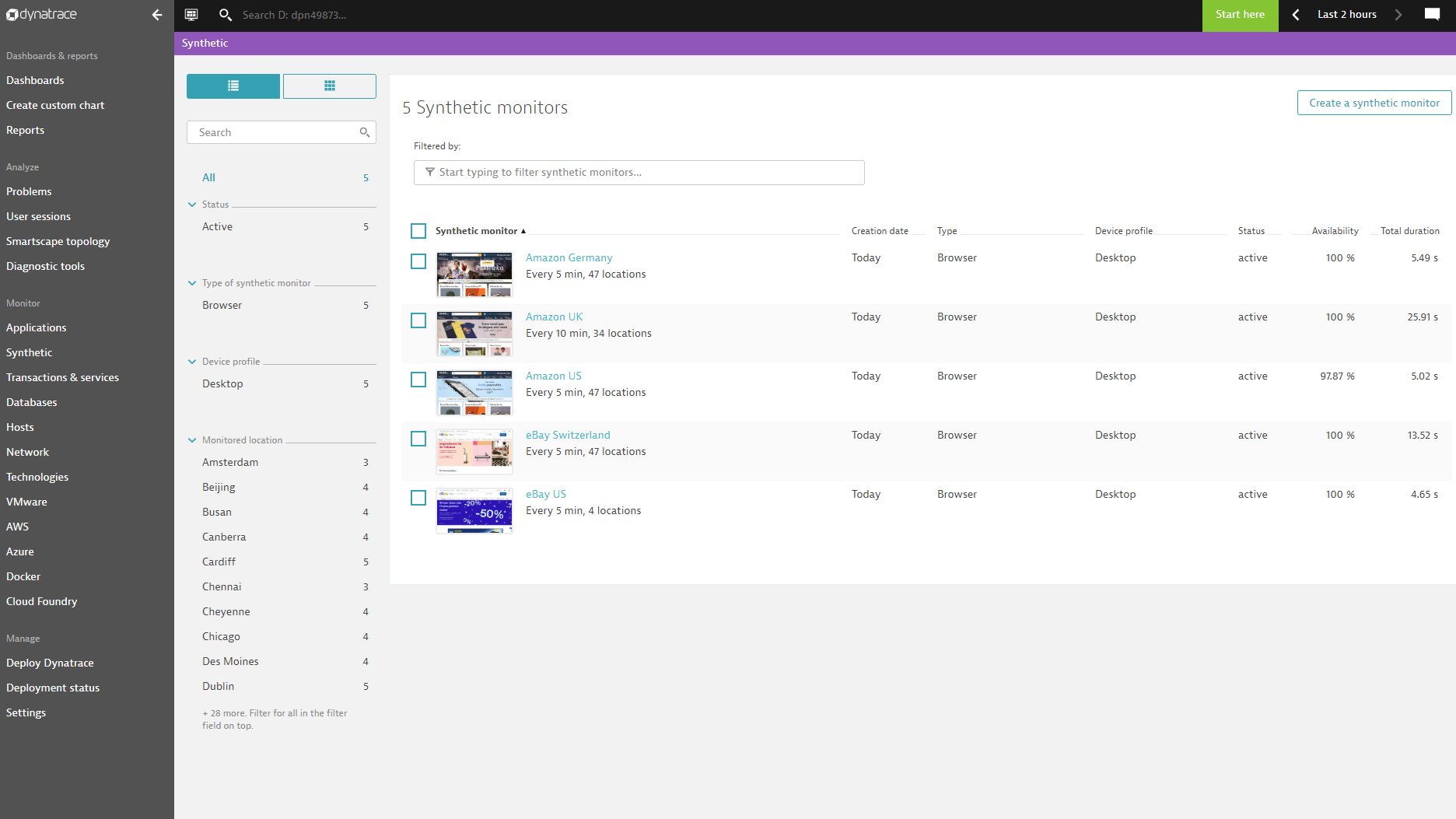
Stay on top with competitive benchmarking
Benchmark your site’s performance directly against your competition to know exactly where you stand.
- Optimize your performance with techniques used by industry leaders to achieve superior results
- Benchmark your site’s performance against the competition’s key pages and transactions in real-time
- Compare application performance from the end-user perspective using last mile and mobile benchmarks
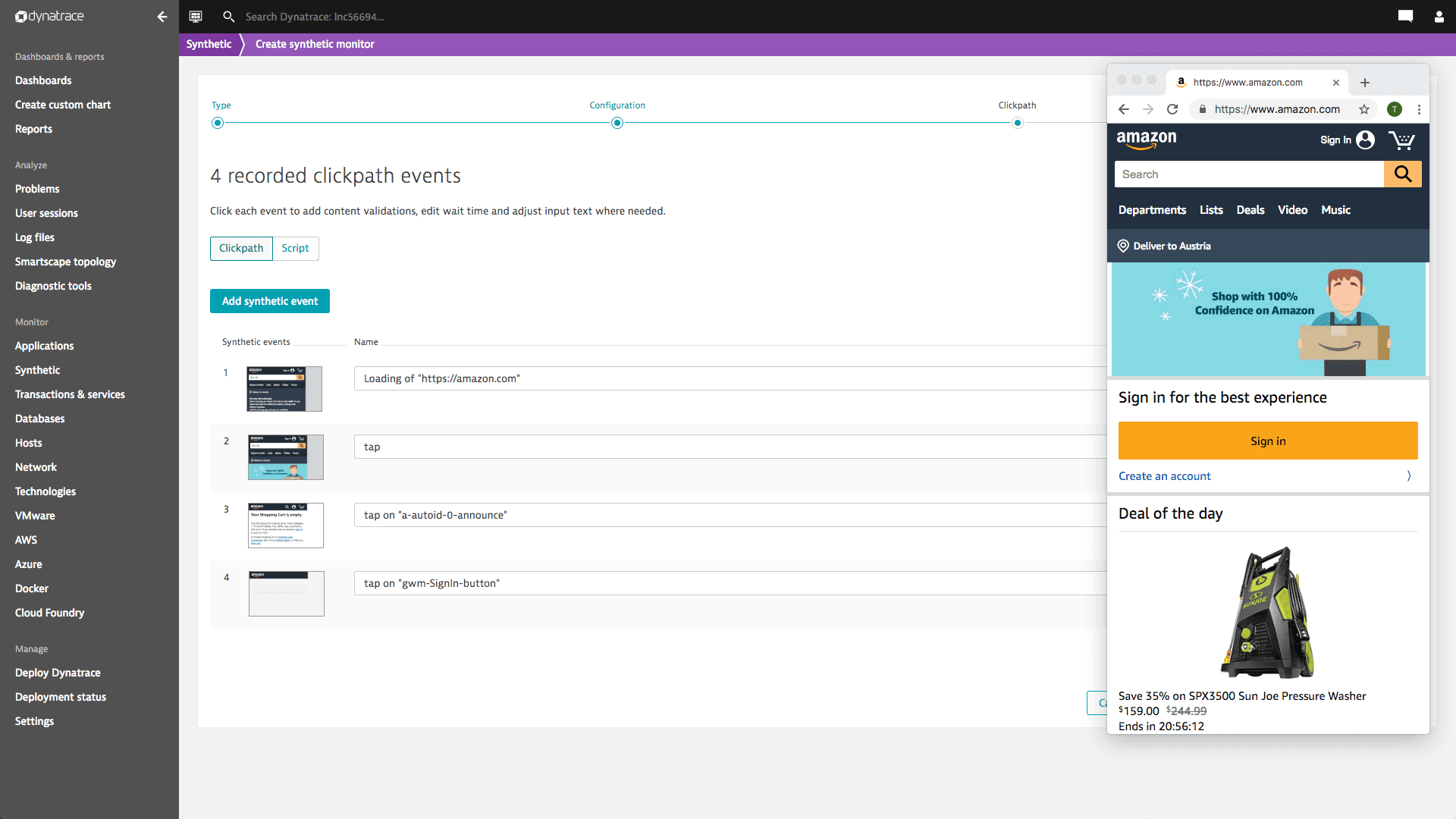
Catch issues early in your software development lifecycle
Incorporate on-demand synthetic tests into your CI/CD pipeline to accelerate innovation, reduce time to market, and lower costs.
- Improve quality with shift-left testing to run synthetic tests early and often
- Measure adherence to service-level objectives (SLOs) to determine whether software versions should progress in the SDLC
- Automatically identify the root cause of issues found via synthetic tests in pre-production and production release validation
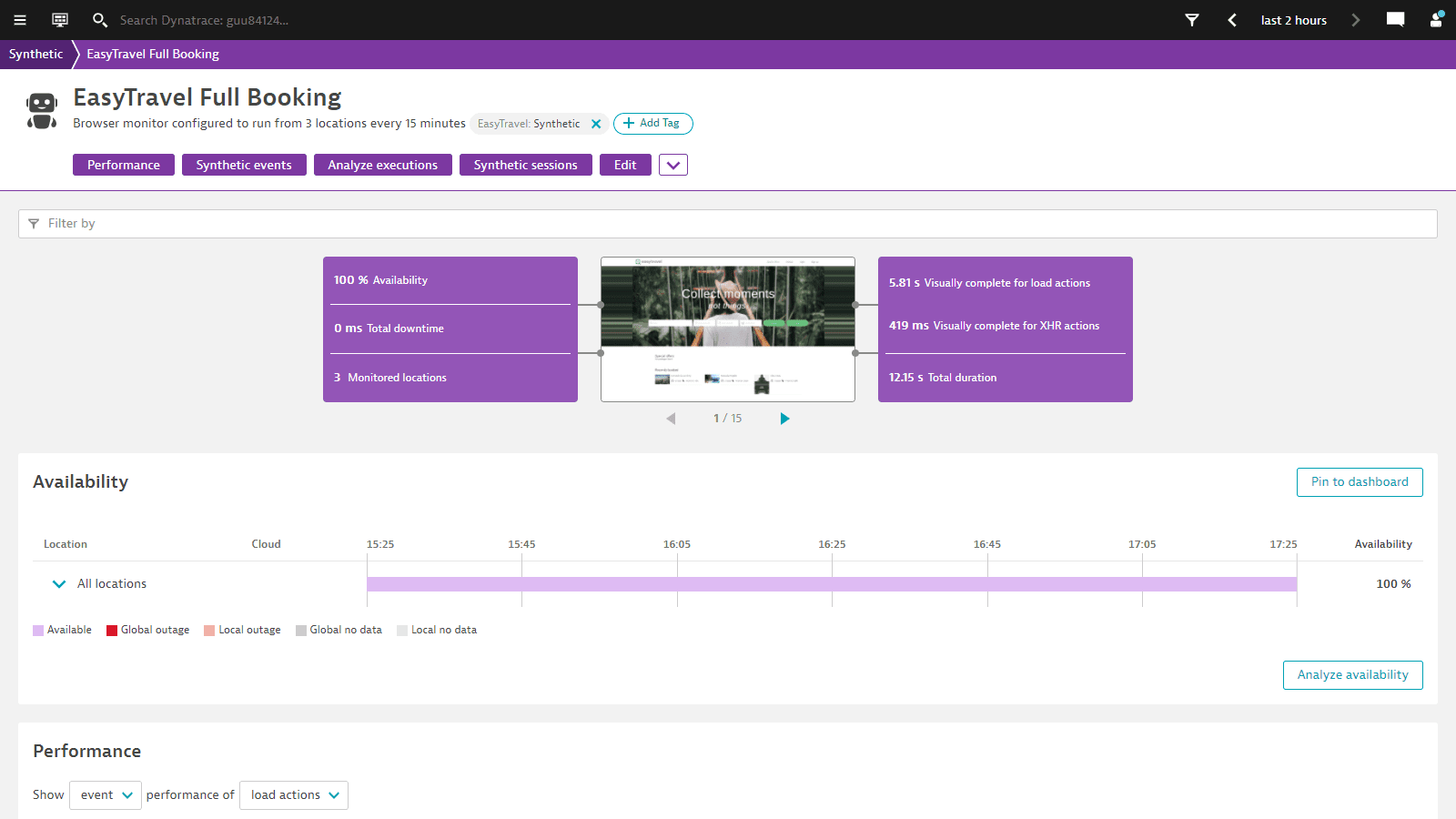
Digital experience monitoring with Dynatrace
-
Real user monitoring
Gain full observability into all activity from every mobile and web user.
-
Mobile App Monitoring
Get AI-powered crash analytics and end-to-end visibility into native mobile applications.
-
Session replay
See exactly what your users see with video-like recordings of every user session.
Expertise-based data analysis and recommendations
Business Insights combines deep Dynatrace expertise with a turnkey big data platform to go beyond application performance and unlock more value to drive business decisions. The services are designed to drive an active performance optimization strategy and culture with synthetic testing technology, even if you don’t have a lot of time or resources in-house. The combination of technology, visualization, and expertise will help you communicate, interrogate and act to optimize your applications and business outcomes.





Start your 15-day free Dynatrace trial today!
Want to see what intelligent observability powered by AI and automation can do for you? Get a free trial of the Dynatrace platform now.


What's new
 2021 CIO Report: How to transform the way teams work to improve collaboration and drive better business outcomes.
2021 CIO Report: How to transform the way teams work to improve collaboration and drive better business outcomes. Read our blog post to find out what synthetic monitoring means for Dynatrace.
Read our blog post to find out what synthetic monitoring means for Dynatrace. What is Digital Experience blog post
What is Digital Experience blog post Learn more about session replay and what it means for Dynatrace.
Learn more about session replay and what it means for Dynatrace. Learn more about real user monitoring (RUM) and how Session Replay enhances it
Learn more about real user monitoring (RUM) and how Session Replay enhances it Performance Clinic: Mastering Dynatrace Synthetics – Advanced Concepts
Performance Clinic: Mastering Dynatrace Synthetics – Advanced Concepts





