

Application Observability
Leverage best-in-class application performance monitoring (APM) to ensure optimal service performance and SLOs, innovate faster, collaborate more efficiently, and deliver more with less.
Prevent, optimize, and resolve application issues
Automate observability for cloud native workloads and microservices
Achieve SLOs at scale, prevent downtime, and reduce MTTR with:
- Continuous topology discovery
- Baselining of response time and error rates for serverless functions, cloud native container services and K8s workloads at scale
- Monitoring of application health, availability and security vulnerabilities with support for OpenTelemetry
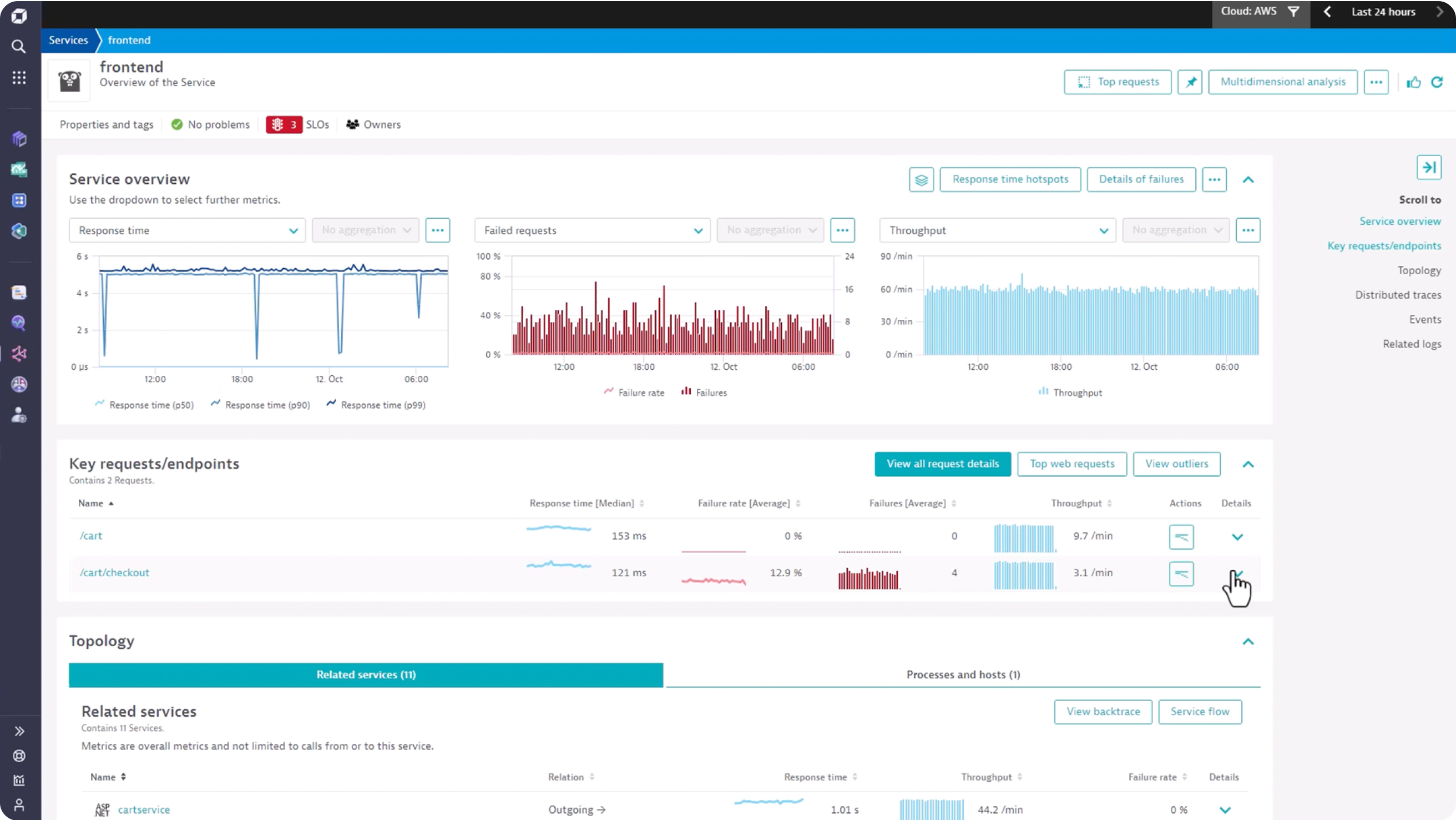
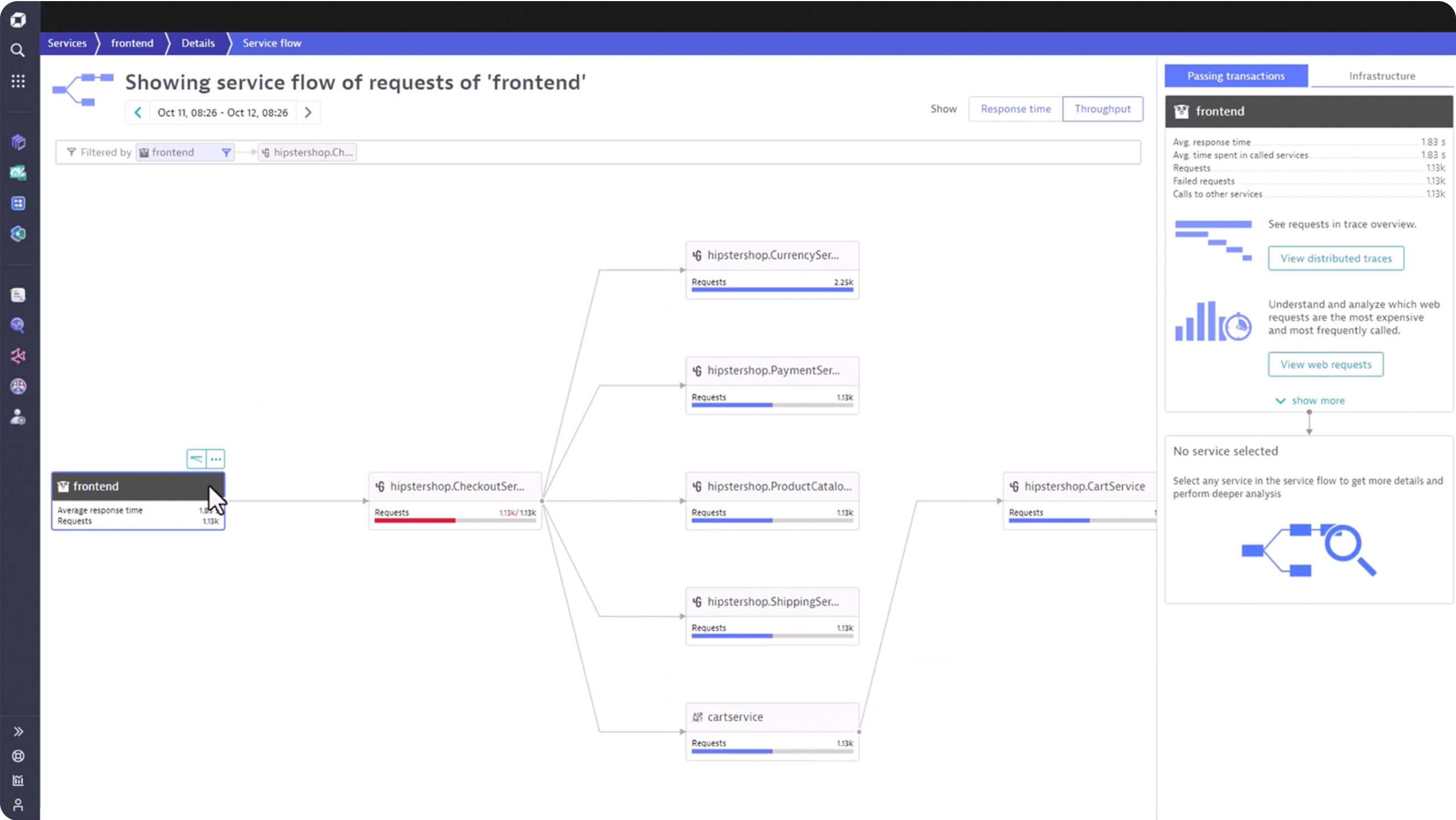
Improve team collaboration and eliminate war rooms
Break down silos with real time application insights and end to end performance analytics through:
- AI powered root cause and impact analytics
- Version and deployment analytics
- Interactive exploratory analytics
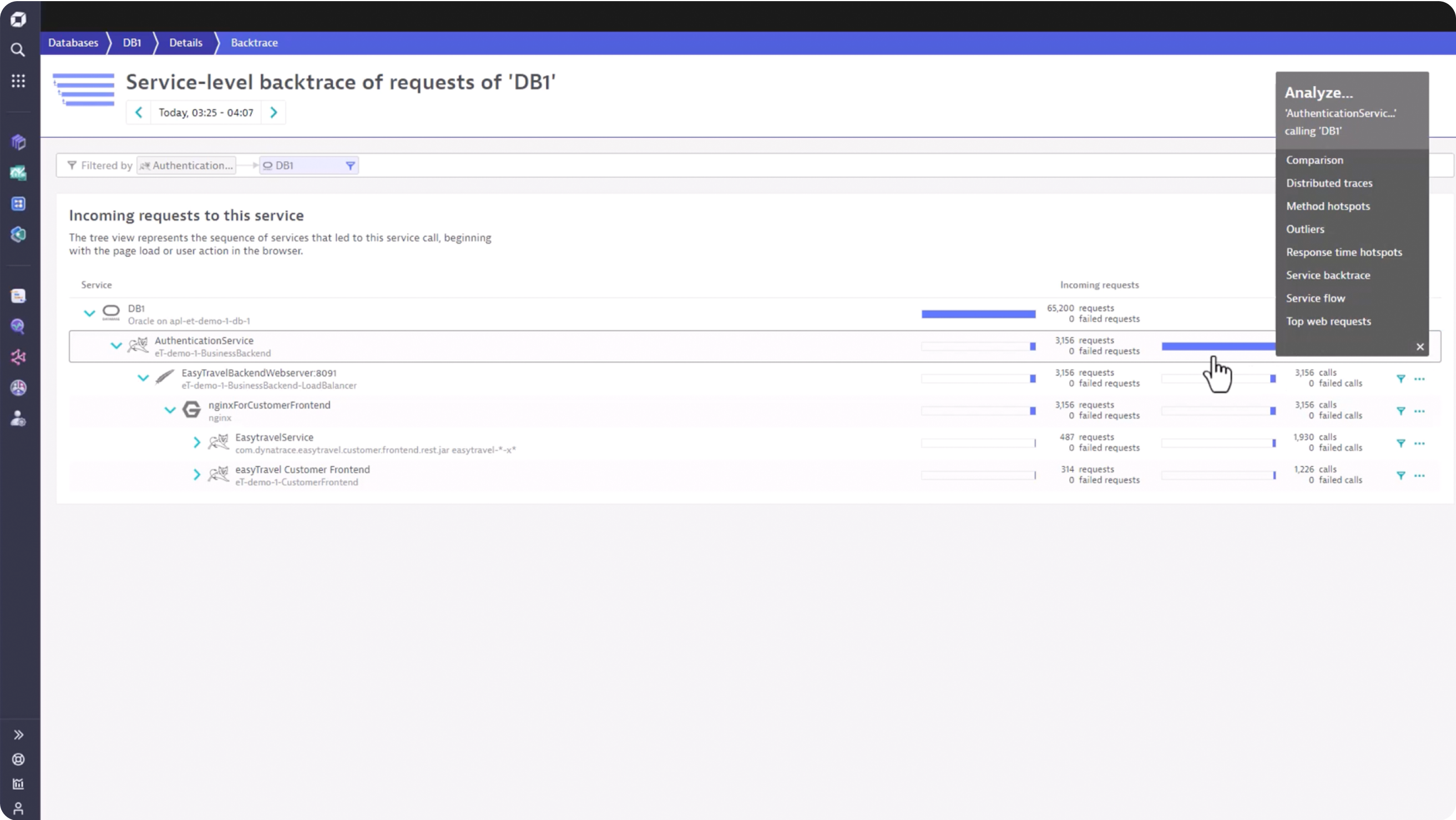
Understand how databases impact application performance
Identify and resolve database issues faster:
- Health metrics for each database instance
- SQL statement performance visibility
- End to end service to database dependency mapping
Improve developer productivity
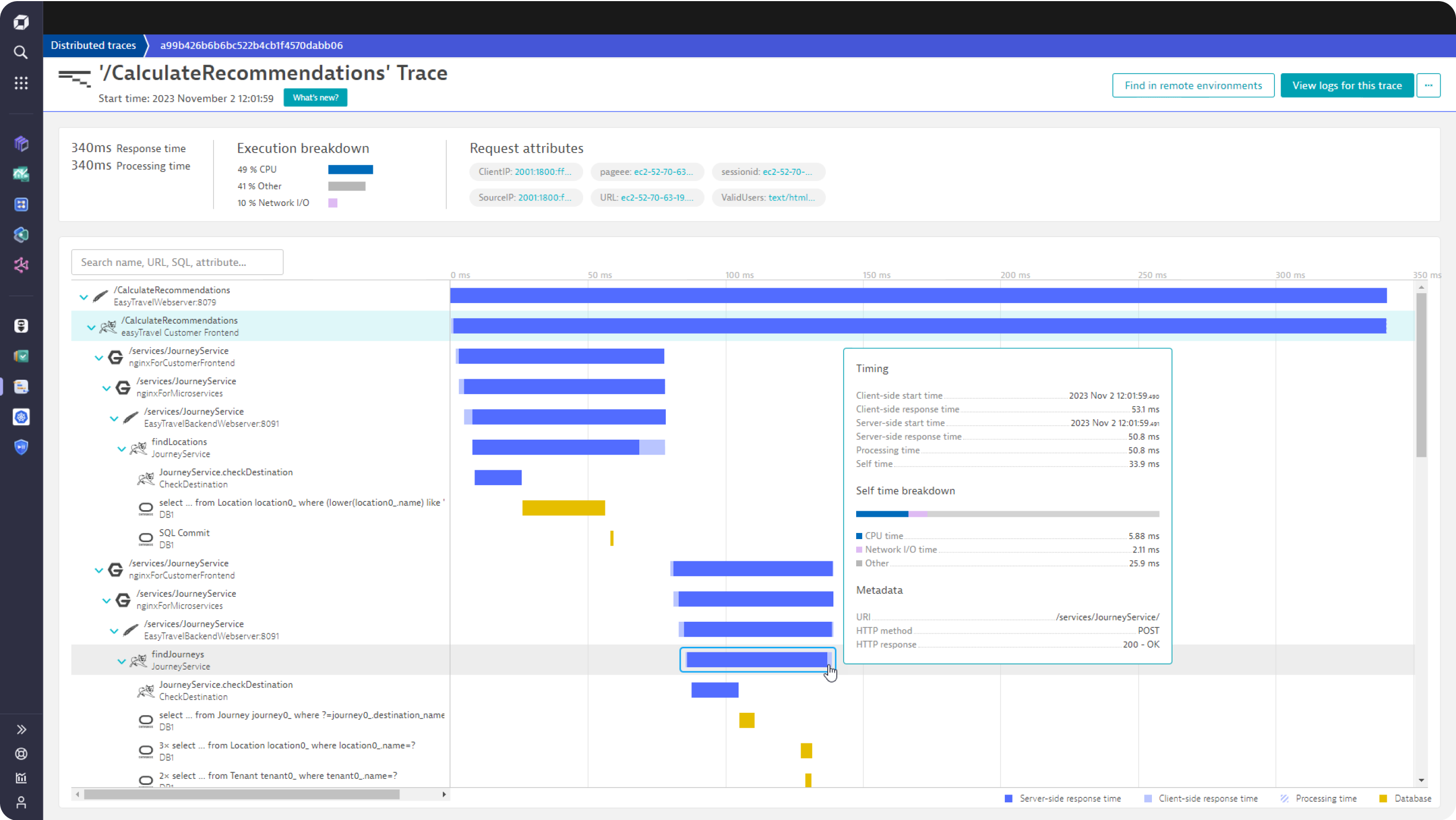
Identify the source of problems with seamless signal integration
Understand details in context across a unified dataset with:
- Enterprise-scale end to end tracing
- Powerful response time and error analysis
- Logs in the context of traces
- OpenTelemetry analytics powered by Grail
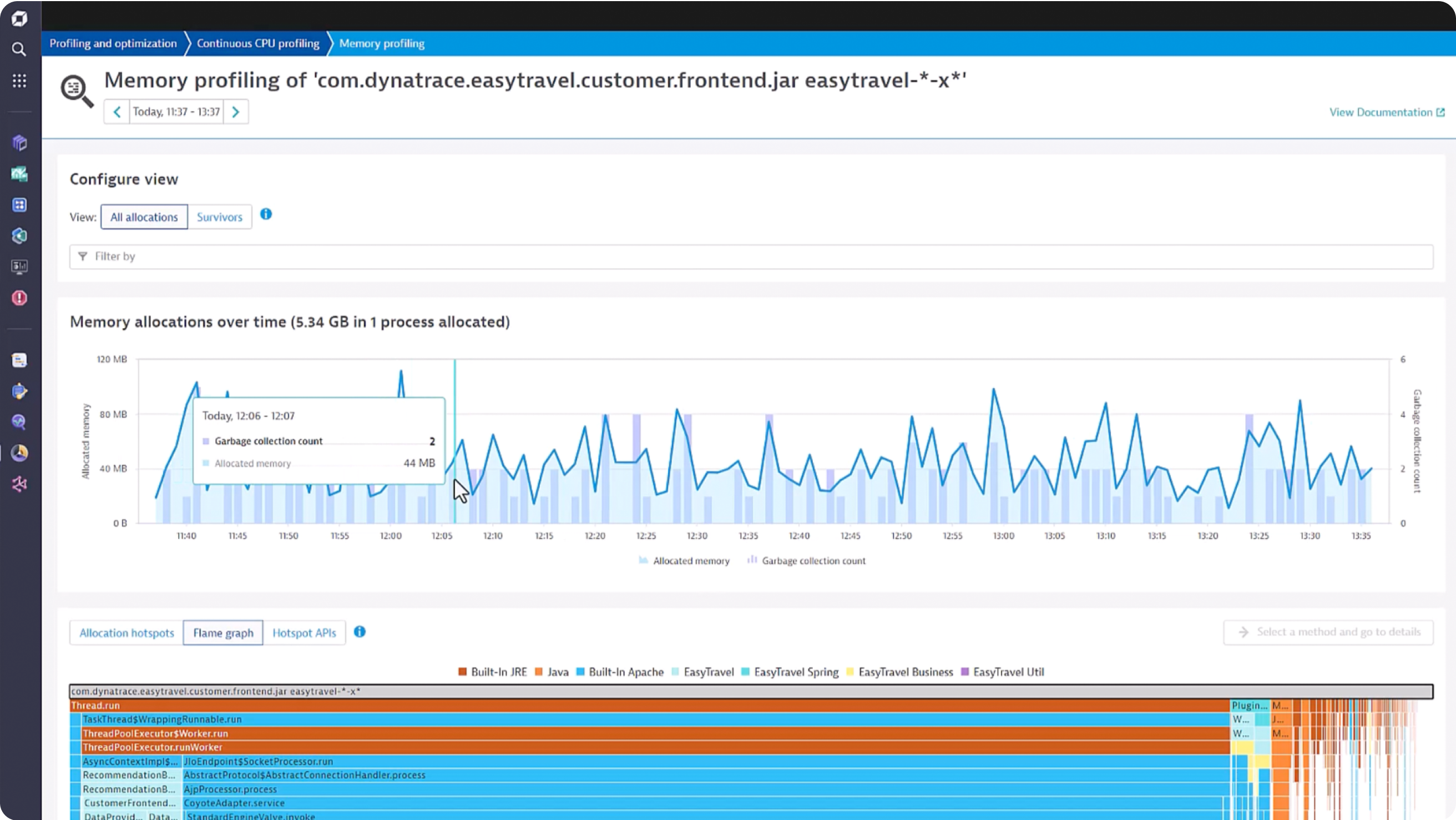
Optimize application efficiency with code level profiling
Reduce end user latency, sync, and locking issues with:
- Continuous production profiling with thread analysis
- Visibility into I/O bottlenecks down to method name
- Code level CPU profiling down to a single method
- Memory and allocation analysis to fix memory leaks and speed up code







Try it free
See our unified observability and security platform in action.
