
Cultural change, automation and continuous delivery allow companies like Amazon, Etsy, Facebook, Target, CapitalOne, Verizon, Netflix and others to deliver more frequent successful new software releases “at the speed of business” (every 11.6 seconds for Amazon). And do it with a 99.9% deployment success rate! If you’ve missed these stories, read Velocity 2015 Highlights, Continuous Delivery 101, or watch Rebuilding an Engineering Culture: DevOps @ Target!

I encourage everyone to look at the links above, and the technical blogs these companies provide, explaining how they achieved rapid deployments with a high success rate. Be aware that your own transformation will not happen overnight, nor will it be successful from start to finish. I had Richard Dominguez, Developer in Operations from PrepSportswear, on my recent DevOps webinar during which he told us they saw 80% of their deployments fail.

This might be a very shocking number but, unfortunately, it reflects what I keep hearing from companies transitioning from traditional enterprise (healthcare, finance, insurance, retail, transportation) to software-defined businesses, with insufficient “Super Hero DevOps” stars to get everything right for everyone.
If your business demands a more rapid deployment model but you’re not sure if you can technically delivery it’s important to measure and monitor whether you are moving into the right direction. Let me show you how to go about Measuring the Business and Technical Success of your Deployments as well as correlating, communicating and taking the right “steering” actions to successfully increase deployment rate and deployment success!
What is a Successful Deployment?
After a recent chat with Brett Hofer – who is helping companies transforming into a DevOps culture – I realized that software defined businesses are measured by the Frequency (how many in a certain time interval) and the Success Rate (percentage of successful deployments) of deployments their organization delivers. The success of a deployment is defined by both Business and Technical goals which can be measured. Here is my quick – not complete by any means – list, which I think is your MUST HAVE to get started:

Let me give you some examples on these listed measures so you can apply this to your own projects:
#1: Availability impacts Brand
The first example is taken from Bloated Web Pages can Make or Break the Day – Lessons Learned from Super Bowl Advertisers. If you are deploying a new feature or a special version of your site/app for a particular marketing or sales event then the key technical metric is: Availability. If the site or app becomes unavailable (technical success metric) it will impact the business goals of attracting new users, converting more users as well as impact to your brand:
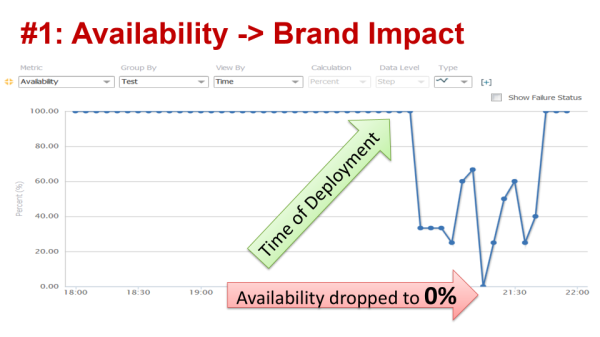
The easiest way to measure availability is to set up Synthetic Monitoring and test your software from those areas where your real end users are supposed to access it. A ping in the same data center doesn’t count!
The brand impact, negative PR and lost users can be monitored by following the number of negative tweets or Facebook postings, the number of calls to your call centers, or the number of tickets opened in your IT department. IT is the first to take the blame!
Why did this deployment fail? Because the site was overloaded with too much content being delivered by the same CDNs that were also delivering content for all other SuperBowl Advertisers. The delivery chain simply couldn’t handle the load. This can be avoided by following common web performance best practices or “GoDaddy’s Keep It Simple Strategy” which showed 100% availability, and even improved web site performance by 4x during the same SuperBowl game.
Metrics for you: Availability, Response Time, Total Page Size, Total Page Objects, Number of 3rd Party Domains
#2: User Experience impacts Conversion
The second example was taken from a Software as a Service (SaaS) website trying to attract more users to the site and actually have them sign up (=Conversion Goal) for their service. The business goal should be achieved by delivering a set of new features on top of an aggressive marketing push.
Instead of just measuring Total Visit Count I always advise to look at Visits by User Experience Index (read the blog or watch the Velocity YouTube Video) to learn whether users have a satisfying, tolerable or frustrating user experience. The following dashboard – showing visit count by user experience index as well as conversion rate – makes it clear the marketing push definitely helped increase the number of visits. After an initial jump in conversions the conversion rate started declining even though more users were lured to the website. A deployment issue on Day 2 also showed a visual correlation between a spike in frustrated users and a drop in conversions:
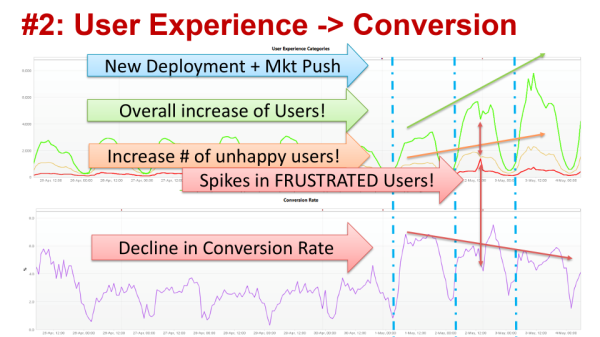
Having these metrics allows marketing to immediately validate whether their campaign actually works. If they just drive more visitors that don’t convert they either targeted the wrong audience or didn’t provide the features the market demands -> this is a clear failure on the part of the business!
If user experience gets worse with an increased number of users it means that the system doesn’t scale, gets slower, or even starts throwing errors. All this impacts user experience which impacts conversion -> this is clearly a technical failure!
Why did this deployment fail? When we did our analysis on the drop in conversions – especially in relation to the spike – it was due to technical scalability issues in the back-end system introduced by set of new features which had a side-effect on each other. Insufficient testing can be blamed for this outcme. The deployment fail on Day 2, which caused the spike, was generated by a similar issue explained in Diagnosing Microservice Anti-Patterns. It was temporarily “fixed by adding more hardware” but both issues also have a long-term impact: more hardware means increased operational costs per user on the platform. After failing once, a bad user experience means that some users won’t give this service a second chance! Better scalability testing and architectural validation would have prevented this!
Metrics for you: Visitors by User Experience Index, Conversion Rate, Failure Rate, Resource Consumption
#3: Resource Consumption impacts ROI
As shown in the previous example, satisfied end users are important to business ! But don’t forget about “Happy Budgets”!
In order to provide users with a satisfactory user experience, modern software architectures automatically scale their environment to ensure a certain response time. This is great, but can hide the fact that a recent deployment – even if it doesn’t impact your end users – is actually a failed deployment because it impacts resource consumption and, therefore, your operational budget. The more resources you need to run your software, the higher the end of month bill you’ll pay for your IT, Cloud or PaaS provider. The following example shows increased Memory Usage which caused a spike in CPU across all servers. Because it is a virtualized environment the additional resources had no impact on end users. This is a failed deployment, and here’s why:
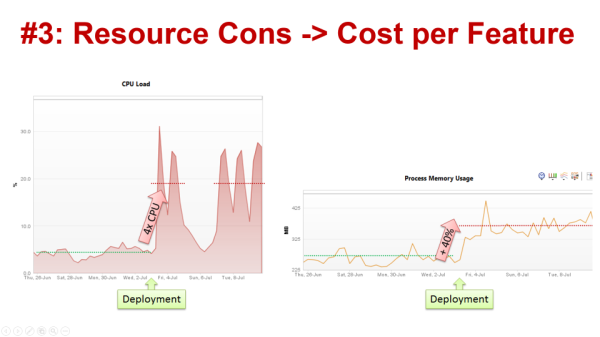
Why did this deployment fail? Root cause was an update of a 3rd party dependency injection library — introduced in one of the builds — that was included in the deployment. Resource consumption was never a metric the technical team considered for each build when they ran their tests. This explains why the change caught them by surprise when their infrastructure team informed them about unusual high memory and CPU consumption in production.
The performance engineering team had to spend extra time re-testing every build to identify which code or configuration change actually introduced this problem! This is example is clearly a technical fail that caused a business fail. The higher costs will either consume your margin on a SaaS-based solution or will increase your operational costs!
Metrics for you: Memory, Network, CPU and Disk Usage by Application, Feature and User
#4: Performance Impacts Behavior
“Using heat maps to obtain actionable application-user insight” was the topic of recent blog, showing how performance and user experience on our self-service community portal (powered by Confluence) impacts end user behavior.
We intended our community portal to allow users to basically help themselves by providing easy and fast access to documentation, tutorials or knowledge base entries. It turns out that the performance of our community changes the click behavior of users trying to find content or the answer to a problem. The slower the community pages, the more likely users will open a support ticket instead of leveraging the self-service aspect of the community.
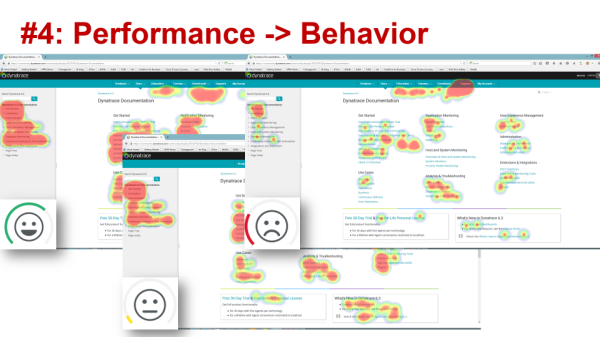
Whenever we make an update to Confluence we must make sure it doesn’t slow down, or we will see an increase in support tickets. In addition to analyzing the performance impact on user behavior, we also analyze what information different types of users consume. This information helps us to ensure deployment or content changes don’t remove “hot content”.
When is a deployment bad? We consider a deployment failed when our users consume less content than before. We watch the number of User Actions our customers, partners, free-trial users and employees click. If that number decreases we know we know we either removed important content or we impact user behavior by through poor performance.
I really encourage you to check out our Dynatrace PureLytics Heat Map GitHub project to learn about more use cases!
Metrics for you: Number of User Actions per Visitor Type, User Action Clicks by User Experience Index
Proactively Increasing Successful Deployment Rate
All these examples of bad deployments have been detected AFTER a change was deployed. While detecting the impact is important, the prevention of these bad deployments is what sets most companies apart from those we want to mimic: Target, Amazon, Netflix, and other leaders.
In my four examples I also provide the technical root cause of failed deployments. Most of these problems are the result of very well-known problem patterns such as “overweight and overly-complex websites”, “bad database access patterns”, “bad service design and call patterns”, “resource leaks” or “too many dependencies between tiers and components”. At Dynatrace Thanks to our PurePath Technology, we at Dynatrace have seen and blogged about these problem patterns as they have been diagnosed. For some time we have been promoting the idea of automating problem pattern detection earlier in the pipeline. Our vision is a software delivery pipeline that stops bad changes as early as possible in order to ensure only good changes make it to production. This leads into a higher success rate of your deployments and, therefore benefits your business!


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum