OpenStack monitoring
AI powered, full stack, and automated application monitoring for OpenStack environments.
Get real-time insights into resource utilization, OpenStack services, service availability, and log files.
What is OpenStack?
OpenStack is an open-source software platform used to develop private- and public-cloud environments. It consists of multiple interdependent microservices. OpenStack provides a production-ready IaaS layer for your applications and virtual machines. Dynatrace provides unprecedented insights into your applications and services running in OpenStack environments, so you always know what's going on.

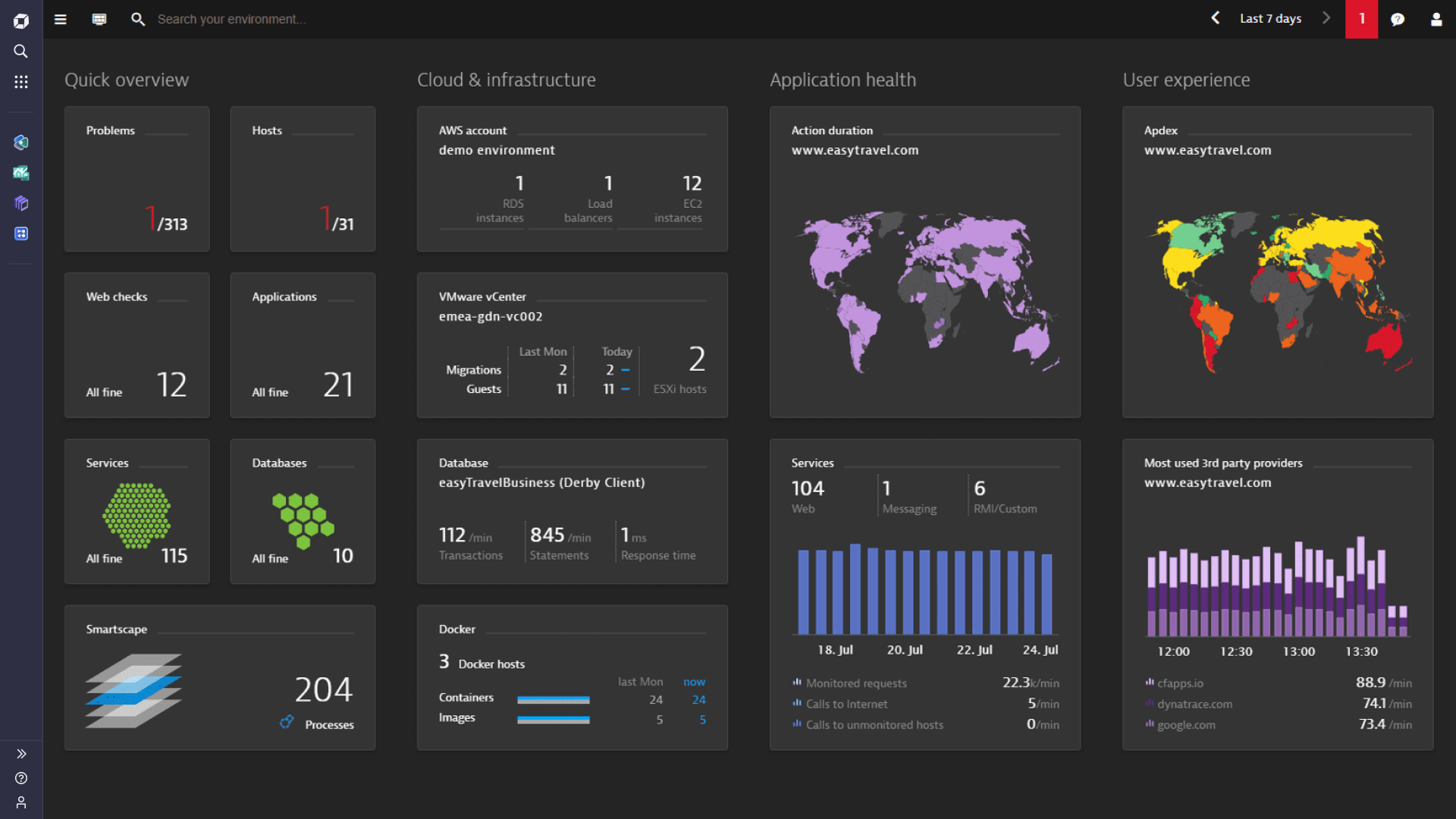
See the full picture of your OpenStack environment in real-time
Too many tools? Lost in complexity?
What you need is a single solution giving insights into your applications and services in your OpenStack environment.
- Auto-discovery of your OpenStack cloud and the entire technology stack in under 5 minutes
- Seamless integration with the entire application environment
- Immediate access to log files pointing to the root cause of system health issues

The most comprehensive set of performance monitoring capabilities for your OpenStack cloud
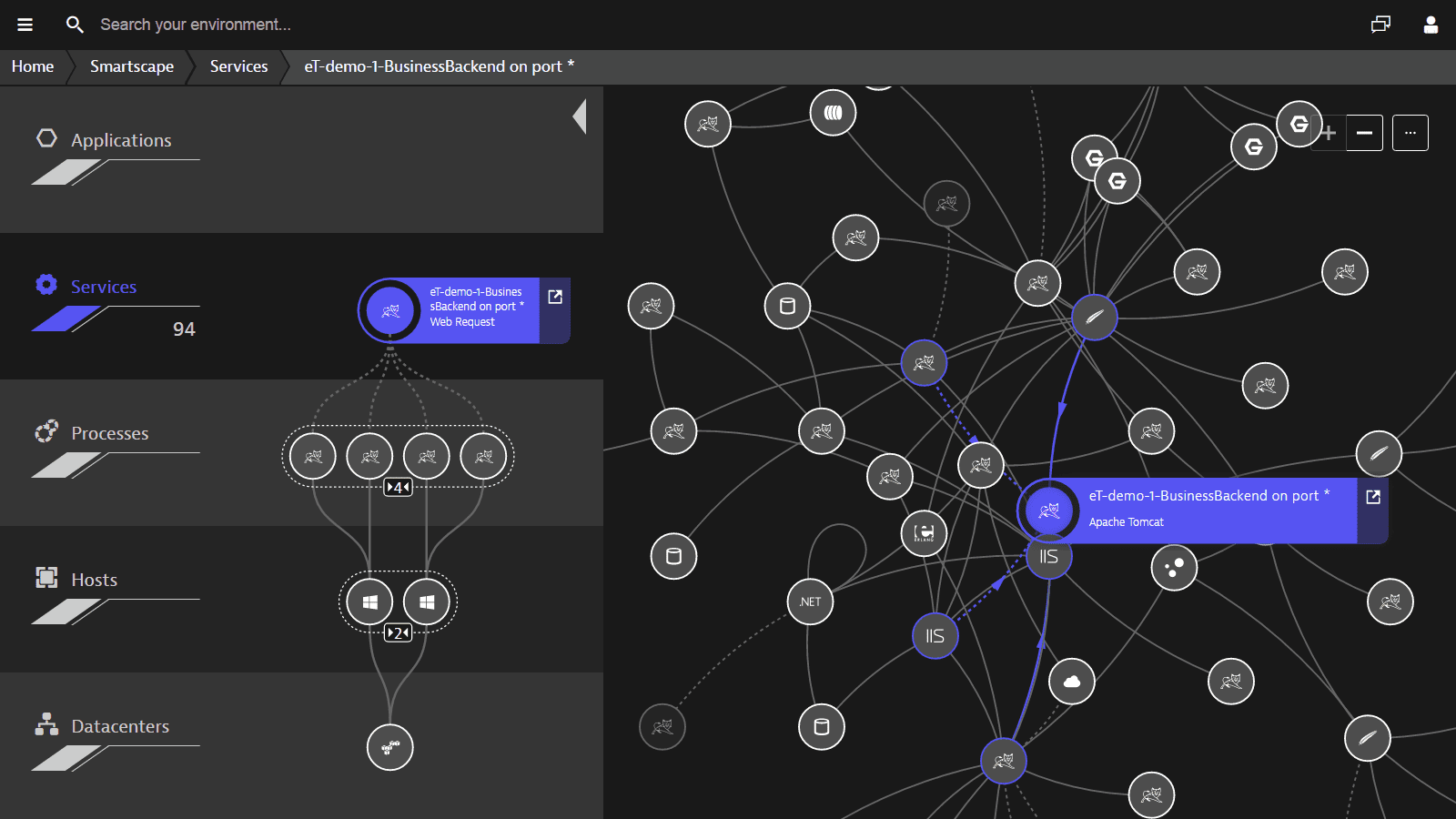
Auto discovery of the full technology stack
- Works out-of-the-box
- Zero configuration
- AI power connects the dots in even the most highly dynamic, fast-moving environments
- The entire application topology visualized in an interactive infographic
- Drill down onto any component for deep-dive code-level details
Built-in log-monitoring in monitoring context
- Get full access without copying or exporting log content to any external storage
- Filter log messages on keywords or time range
- Analyze single or multiple log files at once


To help customers get the most out of Red Hat’s OpenStack offerings and our open hybrid cloud solutions, we work closely with technology companies like Dynatrace that provide powerful and complementary solutions. We look forward to continued collaboration with Dynatrace as an important member of Red Hat’s OpenStack ecosystem.Radhesh Balakrishnan General Manager, Red Hat OpenStack
Start monitoring applications running on OpenStack in under 5 minutes!
You’ll be up and running in under 5 minutes: Sign up, deploy our agent and get unmatched insights out-of-the-box.



We develop Dynatrace hand-in-hand with our biggest customers
Dynatrace has saved us hours and hours in troubleshooting issues.Andy Lofthouse Senior Analyst, Virgin Money
Ready to put the Dynatrace platform to work?
Connect with an observability expert for a live, custom demo of the Dynatrace platform.
