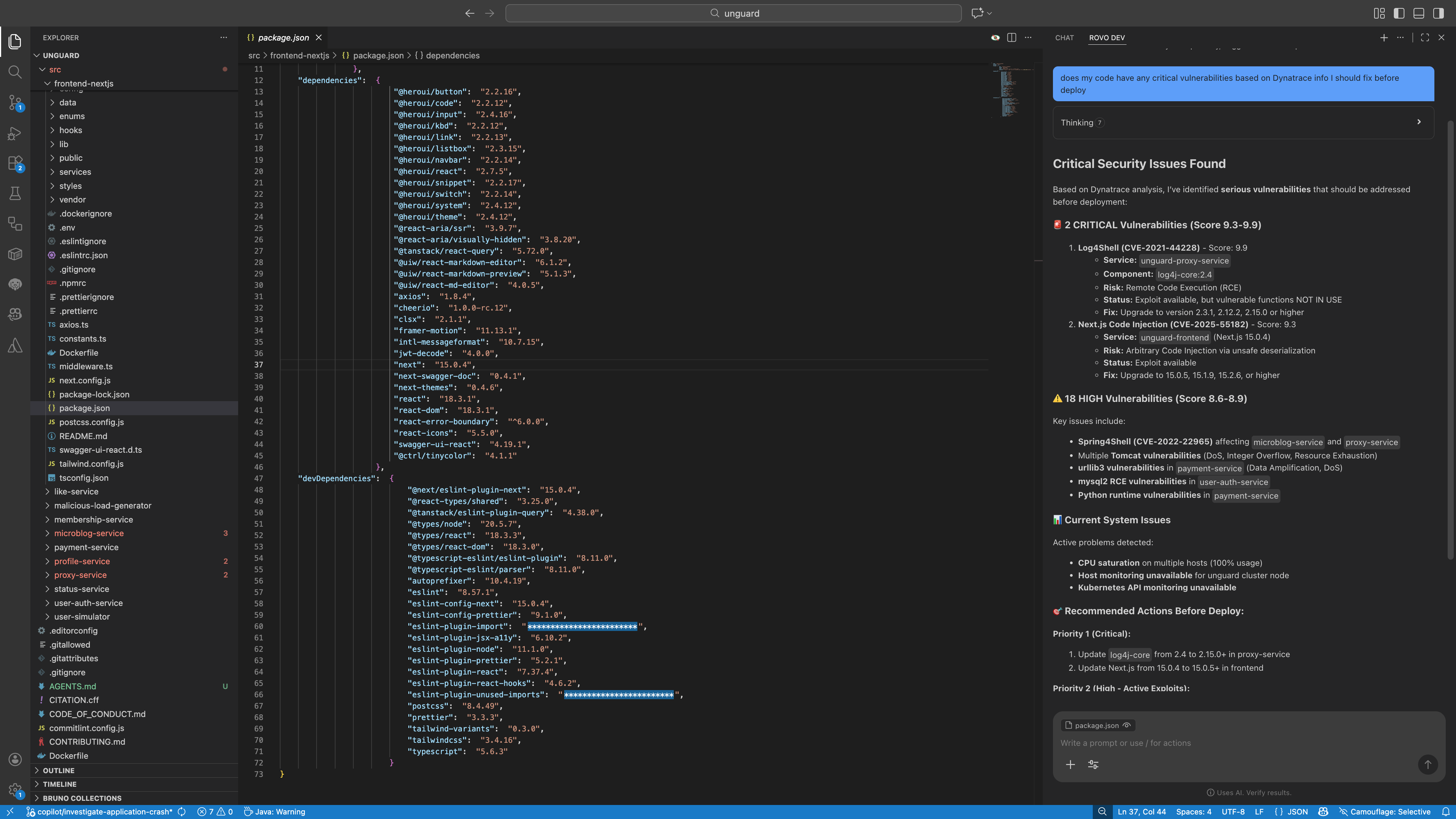
运行时漏洞分析
利用实时上下文持续检测运行时漏洞并重新确定其优先级,以降低风险、消除干扰并加快修复速度。
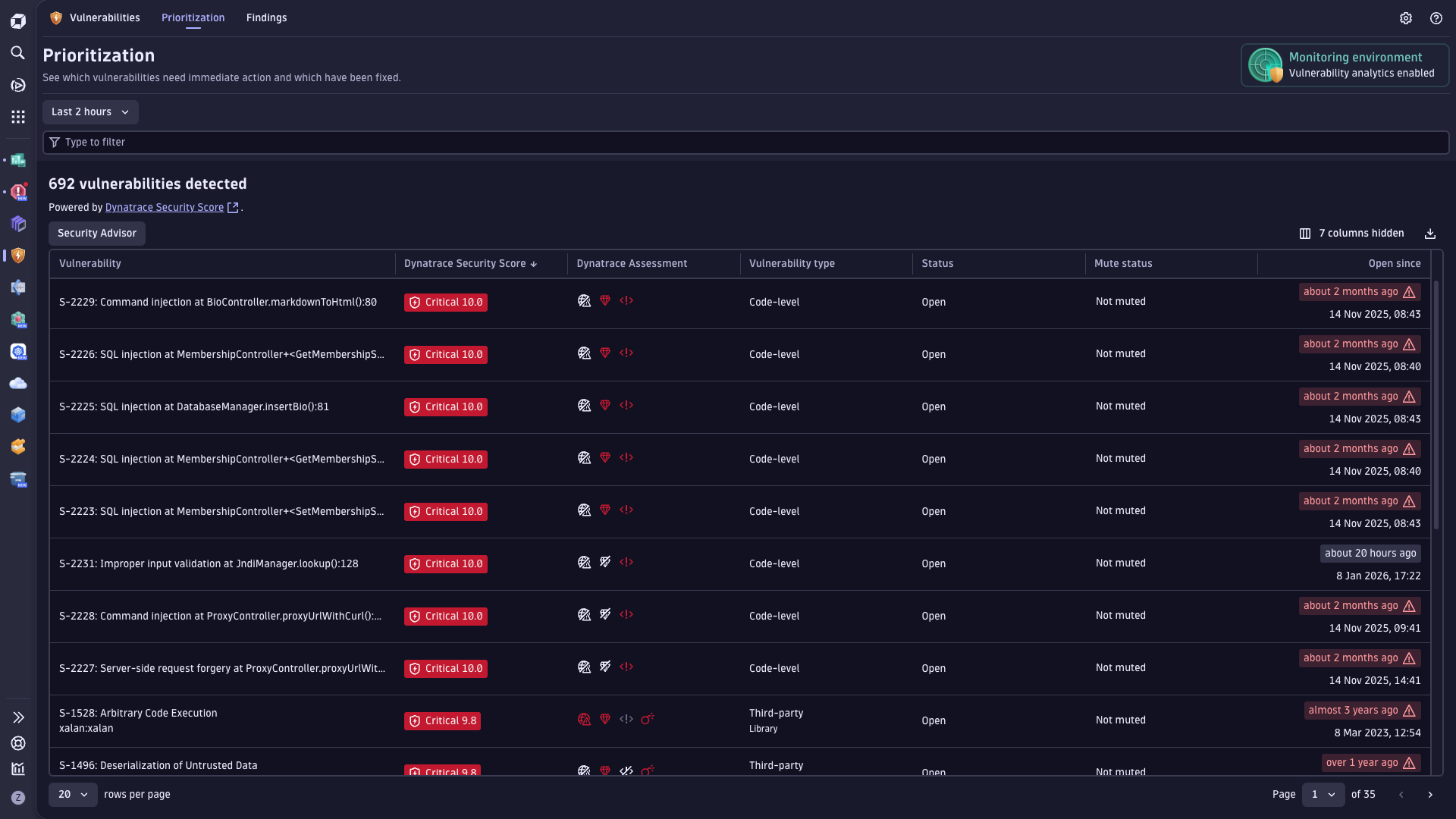

提升生产环境中服务的可靠性
- 通过持续检测并优先处理直接影响在线服务的运行时风险,保障生产环境可靠性。
- 通过深度可见性、快速问题检测和自动化修复,实现 Kubernetes 最大化正常运行时间,缩短平均修复时间。
- 利用跨应用和基础设施的统一可观测性和安全洞察,加速根因分析。
- 通过整合并关联数字生态系统中的数据上下文,消除盲点,防止中断。
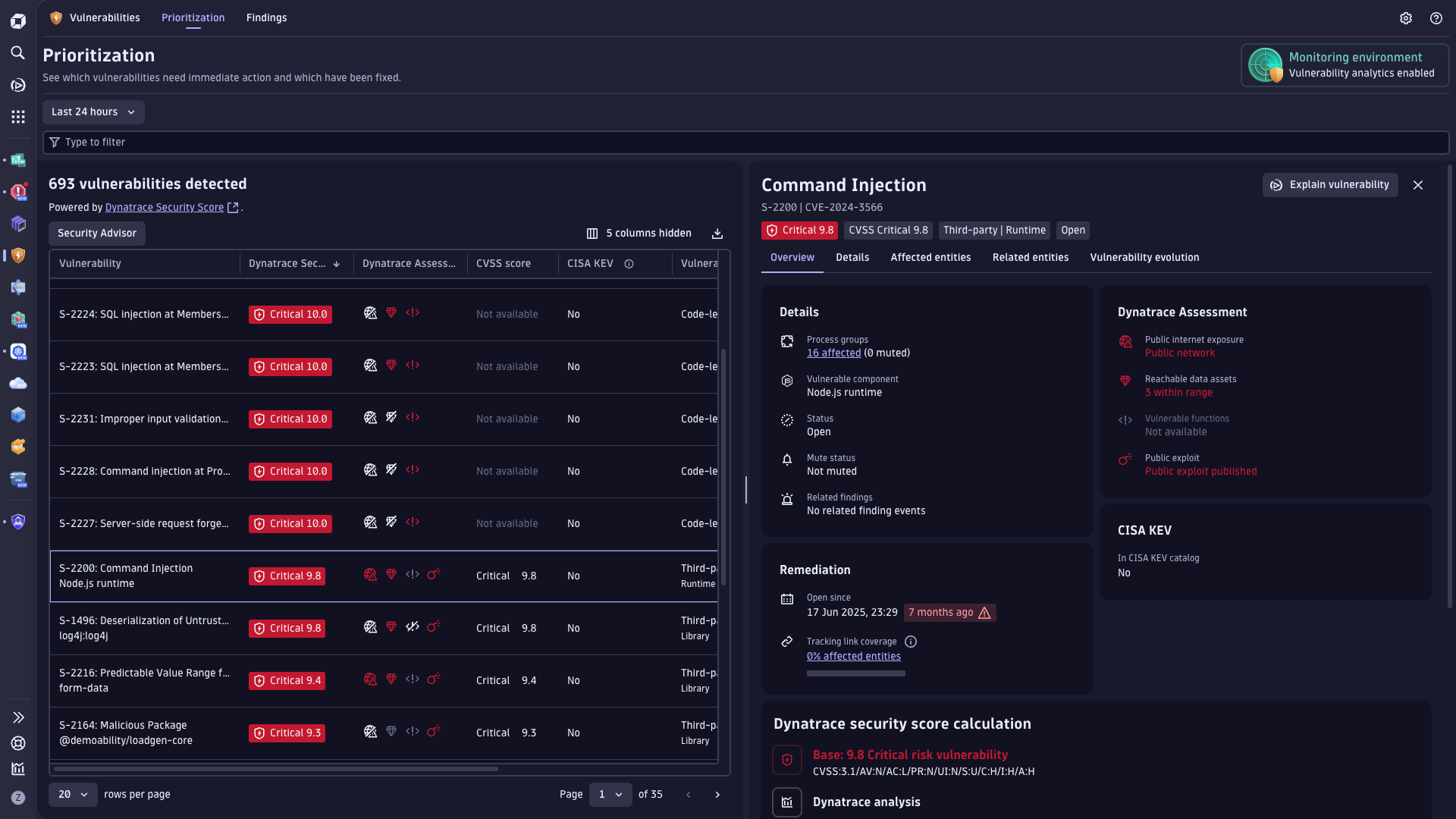
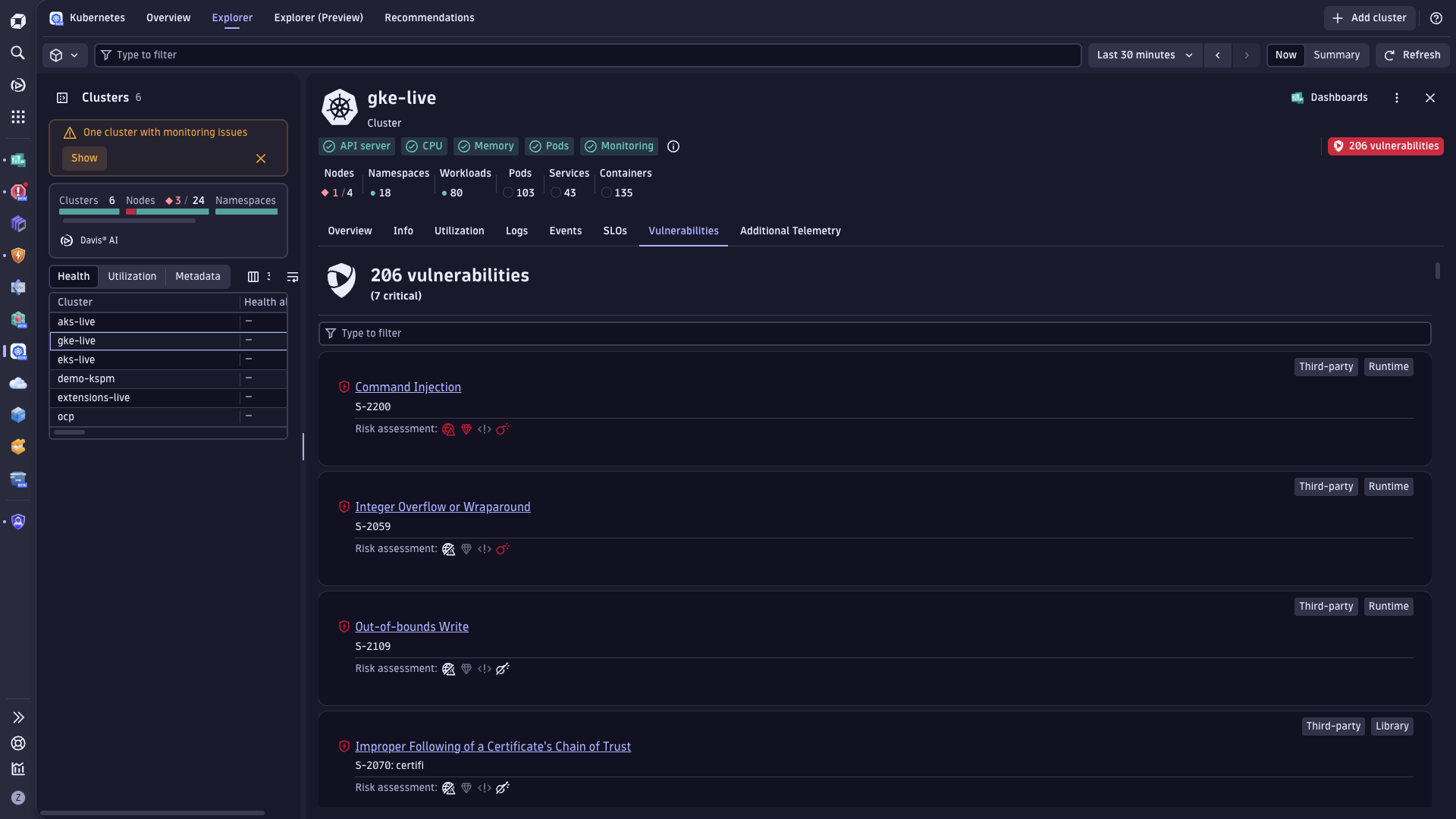
最大化 Kubernetes 工作负载的服务正常运行时间
- 通过主动识别和缓解风险,在问题升级为重大故障或影响用户之前,减少 Kubernetes 停机和服务性能下降。
- 更快速检测、调查并解决问题,显著缩短平均解决时间 (MTTR)。
- 全面掌握应用程序行为、配置风险及第三方依赖关系,实现端到端可见性,消除监控盲区。
- 利用加速修复的工作流程自动恢复服务,减少人工操作。
通过智能体工作流程实现安全修复自动化
- 通过在开发人员的集成开发环境 (IDE) 中直接提供主动的漏洞洞察和建议,将运行时真实情况融入开发早期阶段。
- 利用实时的运行时风险、服务影响和环境变化,自动对漏洞进行分类和优先级排序。
- 通过精准修复建议和智能体工作流程,引导并加速漏洞修复。
- 通过对不可采取行动的问题进行智能排除,并采用闭环验证流程,减少干扰信息与人工操作。