
We’re all aware of the impact that user experience and page speed have on business results for online shopping sites; much has been written about the correlation between web performance and business metrics such as conversions, revenue, and brand image.
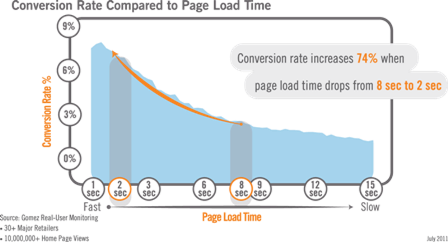
Inside the enterprise, though, we don’t really talk about conversions or abandonment – we have a captive audience, right? Instead, conversations about performance turn towards productivity and user satisfaction. What does remain common is its impact on your brand – the reputation of the IT department and your perceived ability to deliver application services. The shift towards service-oriented IT embodies these business-centric interests, demanding a view of web performance as your users experience it.
So, let’s begin with an obvious conclusion – web performance is similarly important inside the enterprise as it is outside. We should therefore be able to assume that web performance tuning best practices, so well-defined for eCommerce sites, should easily translate to enterprise web applications. To a large degree, this is correct, although I’ll be making the point that they can be enhanced for enterprise web applications. Many of these best practices are embodied in tools and processes, some generic and some specific to common platforms, and are divided into two categories – frontend and backend tuning. Almost a decade ago (!), Steve Souders highlighted what he called the Performance Golden Rule – that 80% of the end-user response time is spent on the frontend, leaving 20% on the backend. (You can find a recent update from Steve here.)
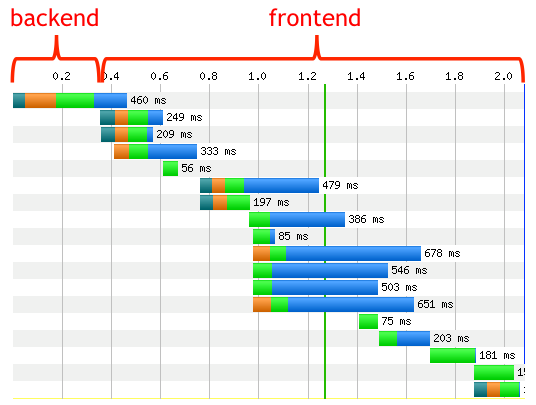
Of course some enterprise apps will involve more complex backend processing than public web sites, but the main point remains valid; a focus on frontend tuning can deliver significant performance benefits. To that end, there exist a number of frontend performance tuning and analysis tools, such as Yslow and PageSpeed. Among other things, these tools evaluate web page performance via a series of well-understood page behaviors, pointing out relative adherence to performance-related best practices topics such as caching, page size, JavaScript sequencing, and many more.
Is it really the network?
What’s so interesting about the frontend that it can be such a significant source of user delay? The network – of course. More specifically, network bandwidth (connection speed) and network latency (browser to web server packet transit delay). And while these tuning tools may not call this out explicitly, many of their tests focus specifically on behaviors that make applications – web pages, in this context – unduly sensitive to these network characteristics. Here’s an abbreviated table of some common tests and their underlying network interest:
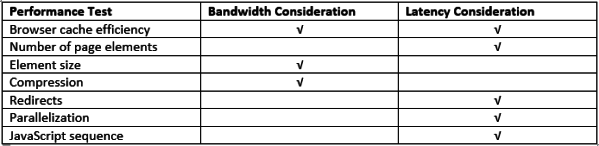
One important point is that these tools treat the network as an unknown abstraction, making some common assumptions:
- You have limited bandwidth.
- Network latency is high.
- You can’t do anything about packet loss.
- You have no significant control over or insight into the network.
For public web sites, these are usually reasonable assumptions. For your enterprise web apps, however, they are not. Think of how your web apps are delivered to your users; in addition to web servers, you might have load balancers, proxy servers, WAN optimization controllers, application delivery controllers and authentication servers. You may have private or managed network connections or use VPNs. You may be setting QoS policies on your routers, and may also manage the desktop environment, including the browser. Some of you will use Citrix.
These differences between public and private web applications are important, especially when it comes to tuning frontend performance. Inside the enterprise, you likely have more visibility into – and control over – the network connecting users to applications, their geographies, the devices they use, and the authentication required – essentially, the entire frontend. You therefore have more opportunities to tune frontend performance for enterprise web applications than you would for public sites. Or the unfortunate corollary – you have more opportunities to negatively impact performance by ignoring the characteristics of your network.
Let’s take a look at some tuning highlights, first using some suggestions from the tools I mentioned. You would prioritize these based on the characteristics of your environment.
Tuning for limited bandwidth
Since you know your network, you should know how much attention needs to be paid to bandwidth-specific tuning. If bandwidth is limited, then the (rather obvious) best practice is to use efficient page design, where the definition of “efficient” is small page payload. Compressing content – gzip, minify, the data redundancy elimination inherent in WAN optimization solutions – are approaches to reducing bandwidth demand, as are browser caching and page designs that emphasize simplicity. The more limited your bandwidth, the more important these tuning considerations become.
Tuning for high latency
More complex a scenario than limited bandwidth, network paths with high latency introduce a number of potential delay sources that can be more difficult to address. Let’s address these one at a time, starting with a few of the PageSpeed/YSlow recommendations (I’ve added one on authentication to their list).
- Use efficient page design, where here, the definition of “efficient” is not so much page size as it is using a small number of page elements, resulting in fewer HTTP requests.
- Minimize TCP handshakes; each new TCP connection incurs one network round-trip delay to set up. To accomplish this, you should be using persistent (keep-alive) connections. It’s been a couple of years since I’ve encountered an environment where persistent connections are disabled, but I know these still exist, often as a result of an adjacent performance tuning effort.
- Increase parallelization by serving content from multiple hosts. This advice is a bit dated, stemming from the days when 2 or 4 parallel connections to a single host were the most a browser could support; most browsers these days support at least 8 parallel connections, reducing the need for adding hosts to accomplish parallelization. (But pay attention to multiple JavaScripts, as these may block parallel downloads.)
- User browser cache efficiently. This means avoiding the “if-modified-since” method, opting instead for expires headers.
- Limit authentication round-trips; NTLM, if you are using it, is a very expensive (performance-wise) challenge-response authentication method. Kerberos is significantly better.
Moving beyond page design, you may also be able to tune your TCP parameters; these can improve performance without touching the application.
- Configure an aggressive slow start algorithm – essentially a larger initial congestion window (CWD). As the congestion window ramps up at the beginning of a new TCP connection, each exchange incurs one network round-trip. It may take 7 or 8 round-trips to reach the equivalent of a fully open standard TCP window of 65535 bytes. (This is only appropriate if you have bandwidth to spare; otherwise, you may end up with a problem I blogged about a couple of weeks ago.)
- Reduce the TCP initial retransmission timer. By default, a new TCP connection starts with a 3000 millisecond initial retransmission timer. As TCP observes actual round-trip times on the connection, this timer is reduced to a value more appropriate to the link’s characteristics. But at the beginning of a new connection, a single dropped packet – a SYN packet, an HTTP GET request, a small response – can add 3 seconds to page load time. Why should you wait 3 seconds to retransmit a dropped packet if you know that your users are at most 300 milliseconds away?
- Examine your inactivity timers. Short inactivity timeout values may be important when you’re dealing with ill-behaved Internet surfers who may stop at your site, then forget about you or disconnect abruptly, but your internal users are generally better-behaved; give them the benefit of the doubt by increasing the TCP timeout value.
I want to reiterate – reinforce – the three performance penalties of a new TCP connection. First, and most obvious, there is the network round-trip time incurred by the SYN/SYN/ACK handshake. Second, each new TCP connection resets the initial retransmission timer – likely to 3 seconds – threatening a severe penalty should a packet be dropped early in the connection’s lifespan. Third, it will reset the congestion window to its initial value – typically two packets – requiring a ramp up through TCP slow start to deliver subsequent payload.
Wrapping it up
The table below summarizes what I’ll politely call frontend design inefficiencies and how they increase performance sensitivity; I’ve covered the more important ones in the discussion, but have included a few additional ones in an attempt to be more comprehensive.
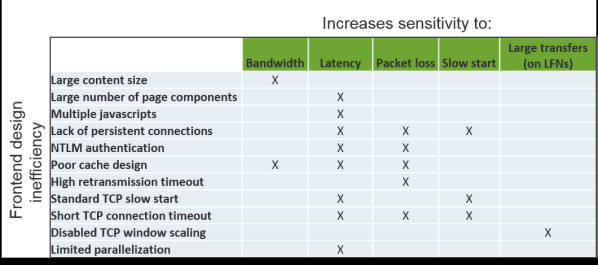
Web applications are designed to use many rather short-lived TCP connections, so paying attention to TCP tuning parameters can deliver significant web performance benefits.
In an upcoming blog, I’ll dive into an example of a typical frontend tuning inefficiency, with a real-world case that ignores many of these tuning best practices, with painful end-user impact.
Let me know if you’ve taken these or other steps to fine-tune front-end web performance in your network.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum