
.NET monitoring
.NET and IIS performance monitoring for your entire application stack, including databases, services, and browser activities
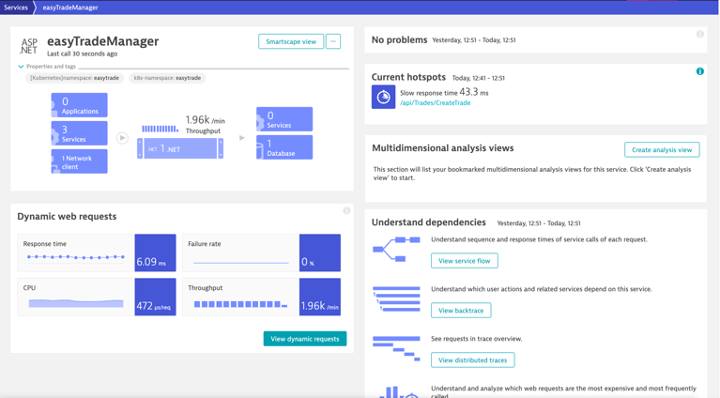
Follow every single transaction, end to end
Dynatrace uses patented PurePath Technology® to capture timing and code-level context for every transaction, across every tier, without gaps or blind spots.
- Drill into all services and components called upon a single user interaction.
- Analyze response times and find hotspots at the method level.
- Understand the impact of methods and database statements on user experience with our unique backtrace capability.
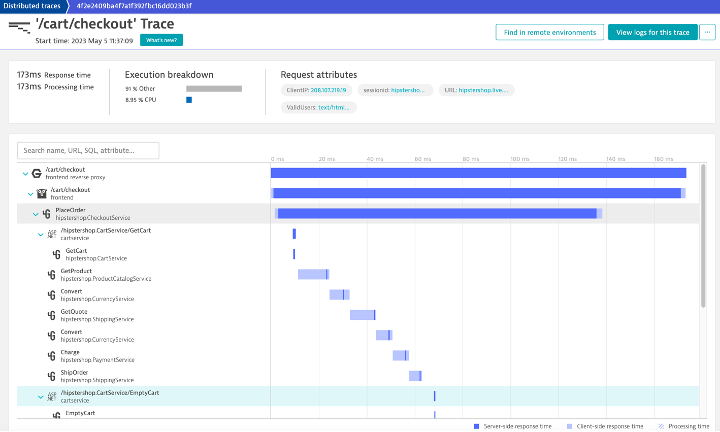
Automatically discover and map applications and infrastructure
Dynatrace automatically detects and visualizes your web application and its dependencies end to end: from website to application to container, infrastructure and cloud.
- Smartscape provides an interactive map of your application across all layers.
- Understand how all components relate to and communicate with one another.
- Get complete visibility into cloud environments where instances are rapidly created and deployed, making it ideal for microservice-centric applications.
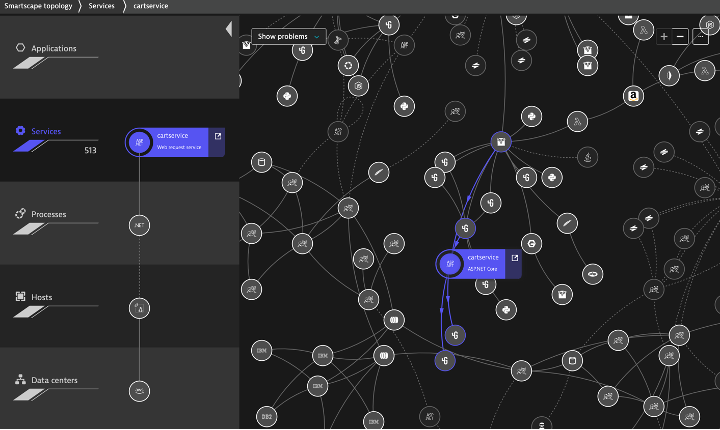
Locate bottlenecks in your application code
Dynatrace enables you to dig into your .NET applications and find hotspots at the code level. Locate problematic methods with CPU or network bottlenecks within the execution call stack.
Your ability to find and resolve performance issues will improve significantly with Dynatrace .NET application performance monitoring.
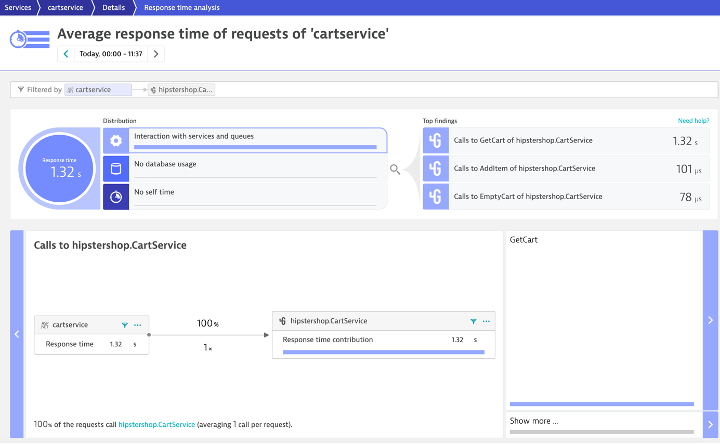
Dynatrace uses AI to determine the root cause of .Net problems!
Dynatrace detects and diagnoses problems in real time, pinpointing the root cause down to the offending code before your customers are even affected.
- Detect availability and performance problems across your stack proactively.
- Directly pinpoint components that are causing problems with big data analytics of billions of dependencies within your application stack.
- Access a visual replay of problem evolution helps you understand how problems evolved over time
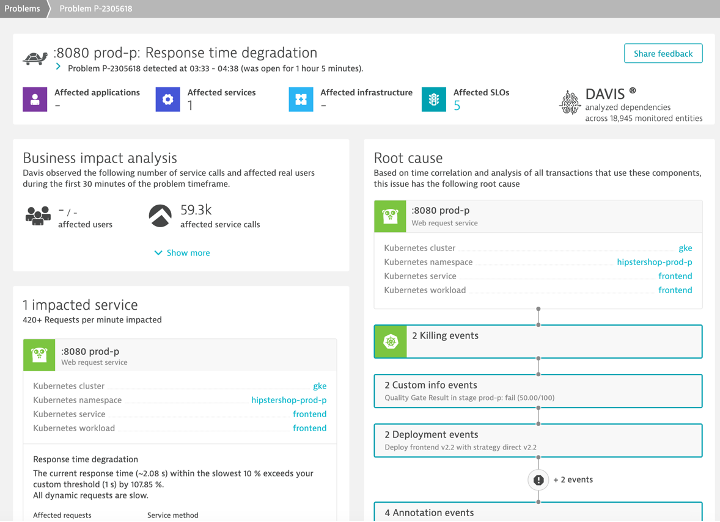
Get the full picture including network health and log file analysis
Dynatrace provides a clear picture of all inbound and outbound process connections over your network interfaces (both physical and virtual) and automatically discovers all log files on your monitored hosts and processes.
- Leverage actual data throughput and quality of network connections between communicating hosts and processes.
- Gain direct access and search the log content of all your system’s mission-critical processes.
- Factor in log messages and networking anomalies into problem root cause analysis.
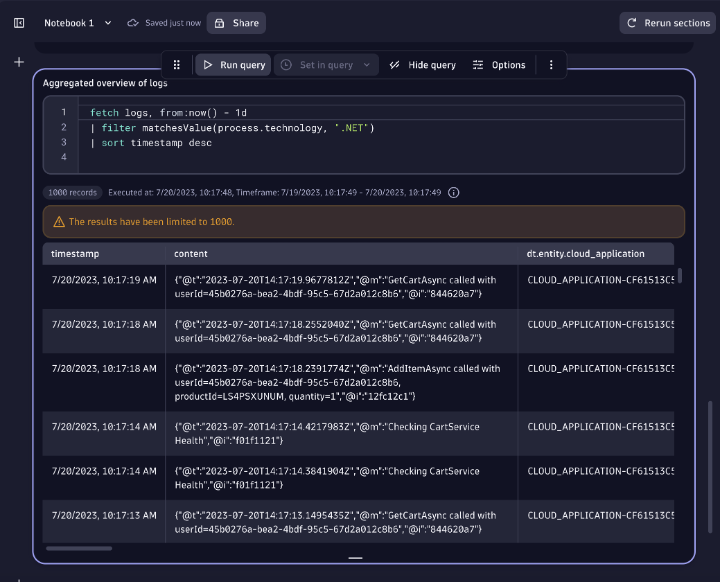
Get all .NET details
- Garbage collection metrics
- Web request and response size
- Busy and idle threads
- .NET managed memory
- Restarts, crashes, deployment changes
- Response time
- Failure rate
- Throughput
- Request and response sizes
- All database statements
- Apdex score
- CPU and memory usage
- Garbage collection suspension time
- Network traffic, TCP requests and retransmissions
- All requests, all dependencies





Sign up now for 15 days of free .NET monitoring!


