
In this 4 part blog series, I am exposing DevOps best practices using a metaphor inspired by the famous 6th century Chinese manuscript: “The Art of War”. It is worth reminding that Sun Tzu, just like me, considered war as a necessary evil, which must be avoided whenever possible. What are we fighting for here? Ultimately, we’re fighting for the absolute best services and features that we can deliver to our customers as quickly as we possibly can, and to eliminate the “War Room” scenario we are all so familiar with.
Welcome back to part two of my four part series on The Art of DevOps. I have previously set the stage, so in this article I will focus on the primary objectives in executing a solid DevOps operation specifically within the Islands of Development. The intel herein revolves around clear, concise communications and sharpening defenses in the continuous delivery pipeline by engaging a higher level of intelligence: advanced performance management.
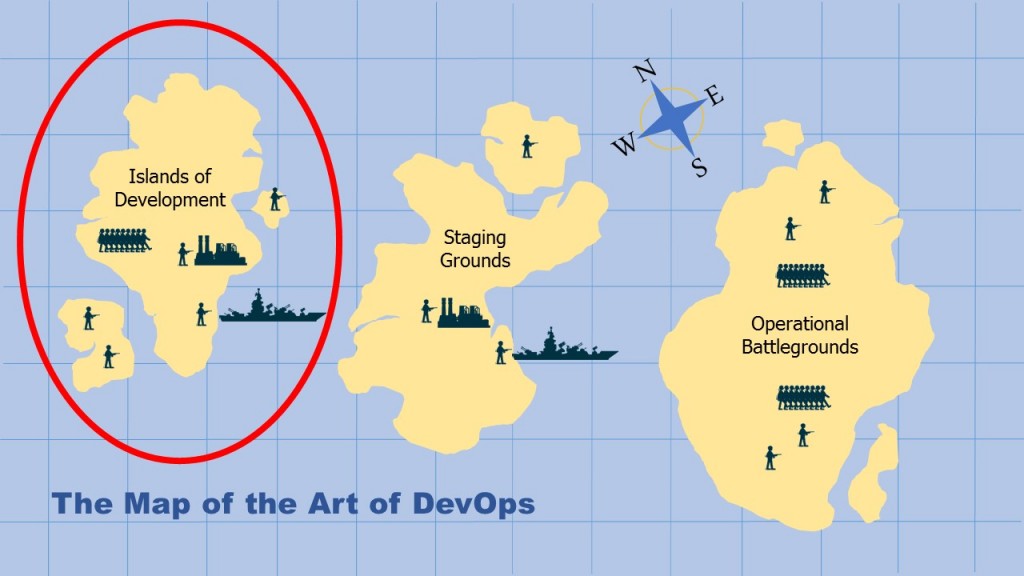
So let’s hunker down and scrutinize the critical drills used to research, build and assemble assets for better quality, precision and readiness before deploying to the Staging Grounds. Many of the units of work to be assembled begin like many other operations. The troops are given a set of orders carefully prioritized by what I’ll call an ‘elite’ team. Each deployment should maximize its value to the battlefield. The elite team in DevOps must optimize their communications between commanders, officers in Development and those in the Operational Battlegrounds. The idea is to develop a world class feedback and delivery loop. (I will cover more communication tactics in Part four of this series). For this stage of the mission to be fully successful, it’s imperative to use consistent tools, aligned by their functional purpose, across the end-to-end delivery process.
To begin, issue each development troop member clear and concise orders. It’s paramount to maintain and prioritize all of these orders in a system of record that provides full traceability back to the original constructor and requester. This enables officers to know their troops and quantify areas of weakness during the development stage. It also enables officers to understand where to target accountability, training and/or rework. It is also important to document, when known, all critical KPIs and SLA goals as part of the appropriate orders.
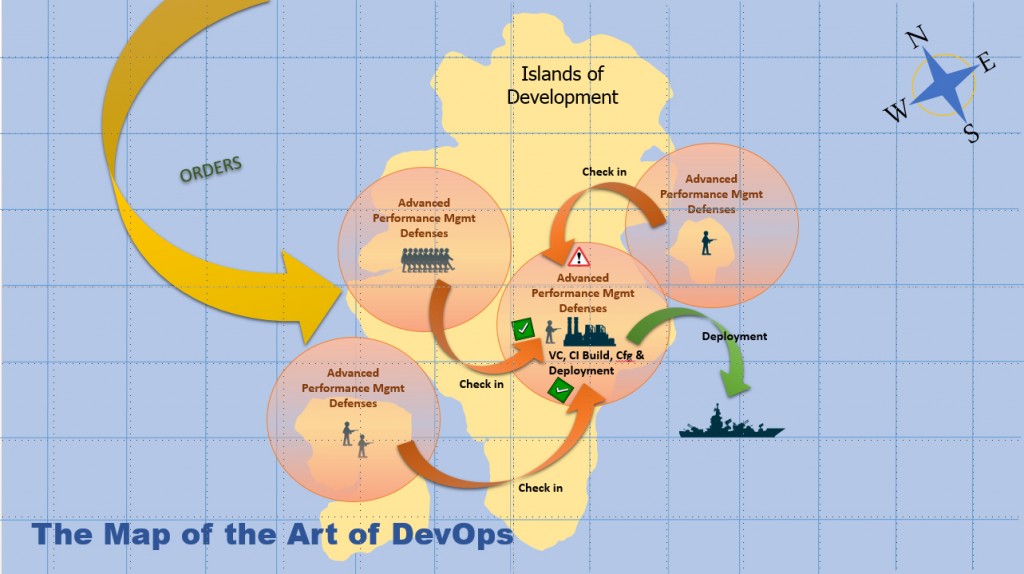
Worthy tracking systems will provide line of sight to weaker troops and assets if casualties are sustained in battle. Although I’m not advocating any one system of tracking, but Jira Agile, Testtrack or Caliber, are a few examples. Once release management and tracking have been established, each developer will have greater incentives to maintain the quality of their asset. Orders can then be traced with confidence throughout a delivery sprint.
Next, let’s look at ways to begin mitigating risk to deployments. Obviously, anything we can do to avoid deploying assets plagued with issues will ultimately save time, money and fatalities on the battlefield. The earlier we can find the issues in the delivery process, the better. Enhancing the developers’ IDEs such as Eclipse, Visual Studio or IntelliJ with advanced performance management is one way to significantly increase the developers’ analysis capabilities. Performance technologies, like Dynatrace, provide incredible insight into the inner workings of developers’ assets, for example:
- Visual representations of runtime transaction flows
- Sequence diagrams
- Degradations in KPIs including, but not limited to:
- Response times
- Method use
- Execution times
- Database query timings
- Exceptions
- Error counts
- Loggings
- Number of remote calls
- Full comparison analysis between either their prior local builds or operational builds
- Comparison analysis between specific transactions currently being repaired vs a corresponding fatal transaction collected during an operational incident.
The technology can also pinpoint issues faster while reducing the need for numerous break points and line-by-line debugging. Call stacks are recorded each time the developer runs the code, enabling end-to-end post mortem analysis of every local run. Not only can the developer prevent a risky check-in but designers such as solution engineers and architects can perform visual architectural validations (as opposed to them having to do full code reviews).
We now move on to a post asset check-in into the version control system that triggers a build on the CI build server. CI servers, such as Jenkins or Bamboo, provide various steps and phases in which the development force can test and piece together all of the inbound assets necessary for deployment. In this ‘construction plant’, we are afforded yet another opportunity to introduce advanced performance management and automation intelligence. During a CI build step, a series of unit testing scripts should be executed to exercise as many of the critical methods as possible. Consider using code coverage tools such as Clover, SonarQube, Team Test or dotCover, to determine the critical areas of the code to be unit tested. Again, I’m not advocating any one particular tool, I’m stressing their importance when forming an optimal line of defense. Once the unit test automation scripts are executed, the rich intelligence collected by an advanced performance management technology can be leveraged. Performance technologies raise alerts or perform automated tasks such as issuing change requests back to the development troops if critical KPIs or SLAs are violated. Using build scripting tools like Maven, Ant or MSBuild, troops can ensure that performance data is aligned and labeled for each build and that actions can be auto-orchestrated based on the performance data collected from each build.
Finally it’s time to automate the infrastructure configurations and deployments. Common tools like Chef and Puppet coordinate infrastructure changes across one or more machines. To ensure each deployment is optimally setup for advanced performance monitoring, the configuration and release management tools must certify that all of the proper performance monitoring settings are configured within each targeted machine. In this way, once the deployment to stage is complete, all operations occurring in the Staging Grounds will be fully tracked, providing maximum situational awareness not only of the build, but the impact that configuration changes may have made as well. After having prepared our optimized and better fortified units we are now able to head off to the Staging Grounds and continue our preparation for battle.

Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum