
If you’re monitoring a large environment you’ve almost certainly come across some aspects of your systems that trigger unwanted problem alerts on a regular basis. Possibly you’re aware of a disk in your environment that’s almost full and you have no intention of swapping out the disk because it’s not a mission critical component. Or maybe you’re running a build and development machine that’s continuously low on resources, but it’s not worth the money to upgrade it.
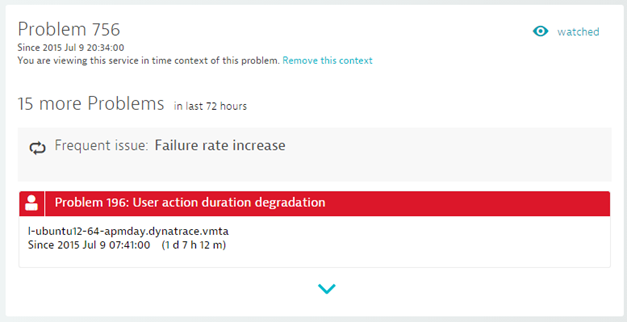
Whatever your reasons, you’ve likely encountered some regularly recurring problem patterns for which you don’t want to be alerted, unless the problem becomes more severe. Such unhealthy–but accepted–situations can generate unwanted “noise” in Dynatrace problem correlation. To avoid alert spamming around such issues, we’ve introduced the concept of frequent issues. Dynatrace detects frequent issues by reviewing recurring instances of the same problem during a specified observation period (for example, one day or one week). If the same problem reoccurs multiple times within the observation period, Dynatrace evaluates the severity of the problem to determine if it’s gotten worse. If the severity hasn’t increased, Dynatrace doesn’t generate an alert for the problem.
The key here is understanding how Dynatrace evaluates the severity of problems. Each problem has a severity value that represents the severity of the threshold breach (for example, a 1 second baseline breach is less severe than a 10 second baseline breach). This value is correlated with the duration of the problem.
So, in terms of evaluating frequent issues, Dynatrace compares the severities and durations of the latest problem alerts for a given entity and only sends out alerts if the severity or duration of a problem has increased. If neither severity or duration have increased, the problem is considered a frequent issues.
Frequent issues are displayed throughout Dynatrace on relevant entity pages; you’ll find them on service, application, and host pages.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum