
What’s your most memorable “blame the network” anecdote? If you’re in network operations, you will likely have many from which to to choose. After all, doesn’t the network always get blamed first? To be fair, other teams often feel the same. Citrix and VMware admins have alternately been touted as “the new network guy,” and the stigma can impact almost anyone in IT.
If you’re on the app team, or represent the business/users, think of recent complaints that might have been worded to blame the network, even without a clear understanding of the actual cause. Surely the intent wasn’t malicious; blaming the network has just become a common way of verbalizing performance frustrations.
I’ve straddled network and application disciplines – NPM and APM technologies – for quite a few years now. Given my network roots, I may still be overly sensitive when the network gets blamed for inefficient application behaviors, but I try to balance this tendency with a healthy skepticism about network service quality; after all, sometimes it is really the network.
When the network itself fails – maybe Southwest really did have a router meltdown – or when it fails to deliver packets reliably, we can all agree, the network needs fixing (and maybe improved redundancy). But those cases are rarer today than ever before. You’re far more likely to encounter subtle, unanticipated interactions between applications and networks that result in disgruntled users – and often in the unsubstantiated claim that the network is slow. This is increasingly true as networks become more application fluent, with firewalls, application delivery platforms, WAN optimization controllers operating above layers 2 and 3, and influencing application performance.
I find it helpful to think of these problems as conflicts between network and application design. Independently, they’re not necessarily bad, but when operating together, the results can be devastating.
A perfect network? Not so fast!
So why can’t we just build a perfect network? I’ll argue (temporarily, at least) that there’s no such thing as a perfect network, at least not without understanding the type of application traffic it is intended to carry.
First, let’s discard the simplistic answer of very high bandwidth and very low latency. (Or, taken to its logical extreme, a network with unlimited bandwidth and zero latency.) Beyond the fact that a network with near-zero latency couldn’t reach remote offices, we must also realize that, while bandwidth may be cheap, it’s not free – especially across large distances or national borders.
What if the network were intended to support only telnet, or more modern thin-client protocols like ICA or PCoIP? You’d then have clear design criteria; a finite amount of bandwidth per concurrent user, with perhaps a maximum of 150 milliseconds of latency between the user device and the server. If you were designing for voice, you might have greater bandwidth requirements, similar latency constraints, and you’d add jitter management to your considerations. What if you were designing for a batch job that archives 200GB monthly to an offline repository in Banff, Alberta? Maybe you’d start with a proposal to use thumb drives and Canada Post. The point is that different application types and their protocols exhibit different sensitivities to core network characteristics such as bandwidth, latency, and jitter.
Can’t we all just get along?
Of course, we generally don’t build single-purpose networks, nor do we design networks with only performance considerations in mind. Instead, we address these performance sensitivities with capabilities designed to improve performance for certain types of applications. Common examples of these capabilities include QoS, caching, and CDNs, as well as WAN optimization techniques that lower data transfer volumes, reduce TCP overhead, and spoof application behavior. Applied judiciously, these capabilities improve application performance and network service quality. The key word here is judiciously; it is not uncommon that wholesale or poorly considered modifications that are intended to improve performance instead produce direct or indirect negative consequences.
It follows, therefore, that improving an application’s performance across the network benefits from an understanding of their likely interactions. Similarly, this understanding helps to narrow the focus of troubleshooting efforts, ignoring the distraction of any premature assumption of network or application culpability.
Into the trenches
This was recently the case when I helped analyze an ongoing performance problem at one of our customer sites. Server-to-server throughput was much lower than expected, and as a result, valuable diagnostic data was inconveniently delayed. The team was pretty sure it was the network’s fault; after all, hundreds of customers use the application with no problems. In fact, even at this customer, everything was working fine until they moved one of the servers to a different data center; the only thing different was the network.
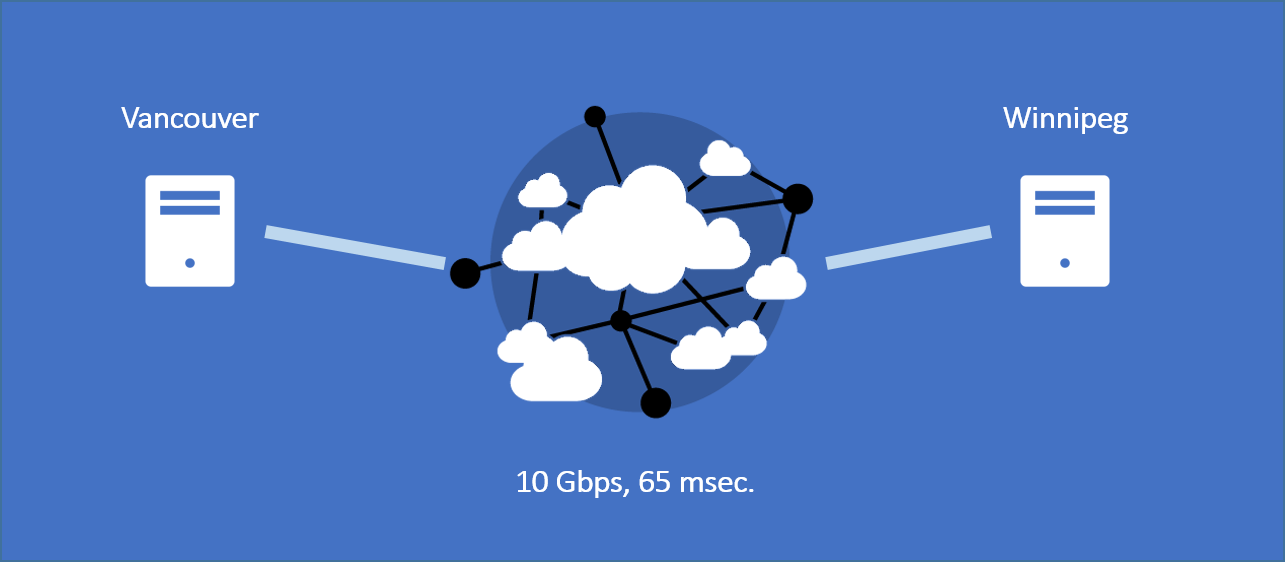
Aha! Knowing that certain application and TCP behaviors lead to degraded performance in direct correlation to increasing network latency, I derived a simple line of initial questioning for the virtual war room.
- Is the new latency in line with expected latency based on distance? (Here I’m simply considering routing path inefficiencies.)
Yes; 65 milliseconds (round-trip) is excellent based on the distance covered. - How chatty is the application? How many application turns? How many bytes are transferred for each application request?
The application writes files of up to 512KB. Each write incurs one handshake turn and one file transfer turn. - What size is the receiving node’s TCP window?
Unknown. - Does the application write to the socket in block mode? Or stream mode?
Stream mode (one file at a time).
Confident that the network would provide an unbiased source of diagnostic data (can’t shake those network roots), I asked for a trace file. Upon examining the trace, I quickly confirmed a TCP receive window constraint.
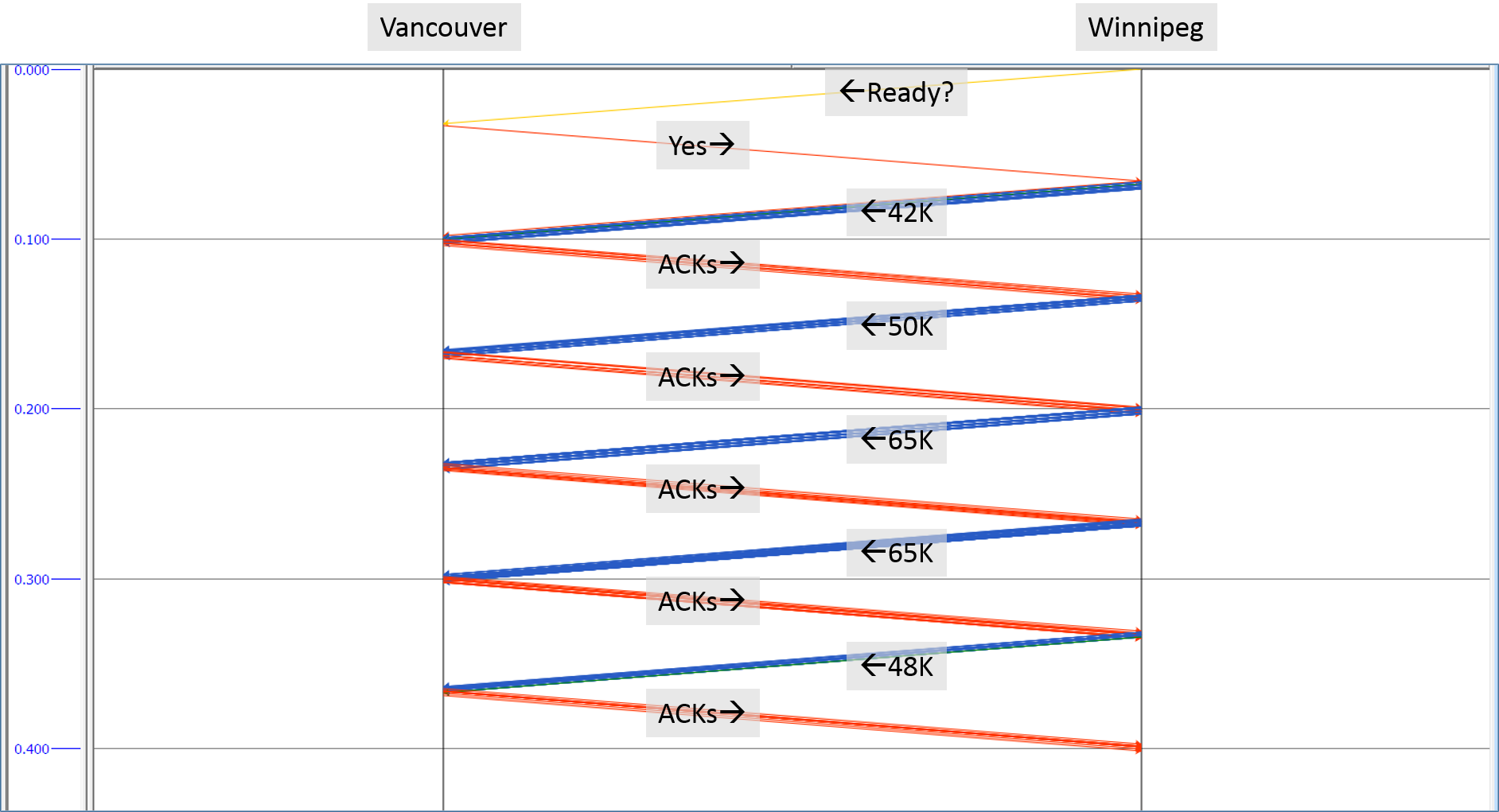
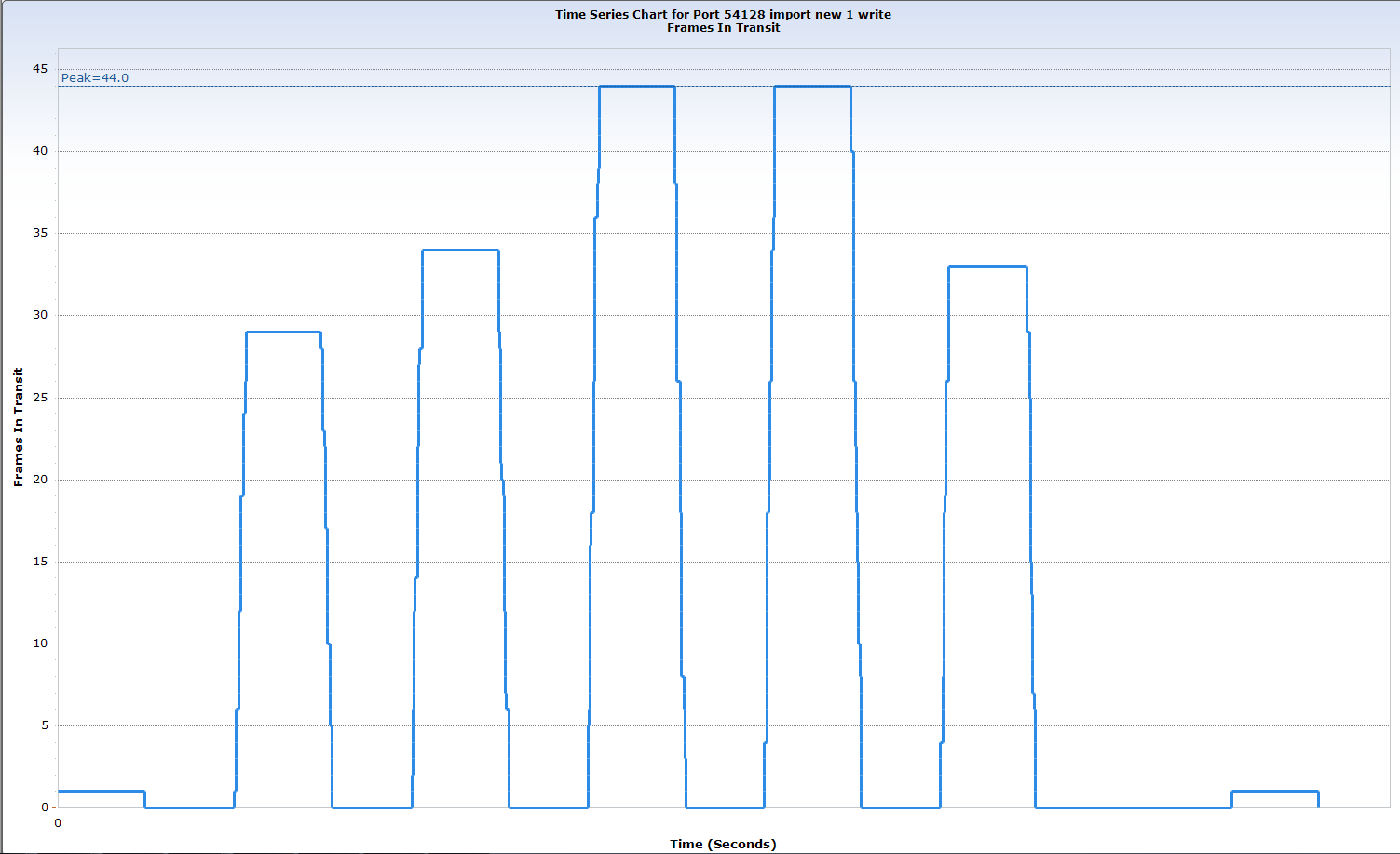
Even with the TCP Window Scaling option enabled, the receiver’s window never increased above about 65KB; limiting the sender’s congestion window to 44 packets. With plenty of bandwidth, why didn’t the window scale to permit greater throughput?
The developer hinted at the answer by identifying that the application allocates a receive buffer of 128KB – reminding me that applications are able to set their own receive buffer size as they open a socket connection. This value was fine for co-located server-to-server communications, and also worked well for remote communications where the volume of files to be transferred was small. But in our high-bandwidth, high-latency, high traffic volume environment, the small buffer allocated by the app exposed a TCP flow control inefficiency severe enough to cause a problem.
So – was this a network problem? Or an application problem?
As I have written in a previous post (on front-end tuning), there are often two interrelated causes behind performance constraints, one physical (the infrastructure) and one logical (the app and the protocols used); it is possible to improve performance by tackling either one. In this simple example, the physical cause is the network latency, while the logical cause is the small TCP window size imposed by the application.
Good war rooms?
In a recent research note*, Gartner recommends convening war rooms to foster collaboration and exchange best practices. (Wait a minute; haven’t performance management vendors been promising the end of war rooms?) This was a great example; I learned a few new things about Linux networking and gained new insight into how buffer allocation decisions are made. And our dev and field teams learned a few things as well.
What are your “blame the network” stories? You can send me your trace files, especially if you’d like to be profiled in this space.
________________________________________
* Gartner Research Note, Use Data- and Analytics-Centric Processes with a Focus on Wire Data to Future-Proof Availability and Performance Management, Will Cappelli and Vivek Bhalla, 10 March 2016.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum