
In my previous blog I addressed how we use Dynatrace on Dynatrace in our Continuous Functional Testing Environment. During that same visit to our engineering lab in Linz, Austria I also spoke with Thomas Steinmaurer, Performance Architect for Dynatrace. He oversees our Continuous Performance Environment. Dynatrace builds are deployed daily. Different load patterns are constantly running simulating traffic of thousands of agents. For this purpose we wrote our own performance testing tool because we have some special requirements to simulate that type of load.
Like Stefan, who told me his story about how Dynatrace helps him to get faster feedback on continuous functional tests, Thomas told me how Dynatrace helps him detecting performance regressions introduced through code changes from build to build.
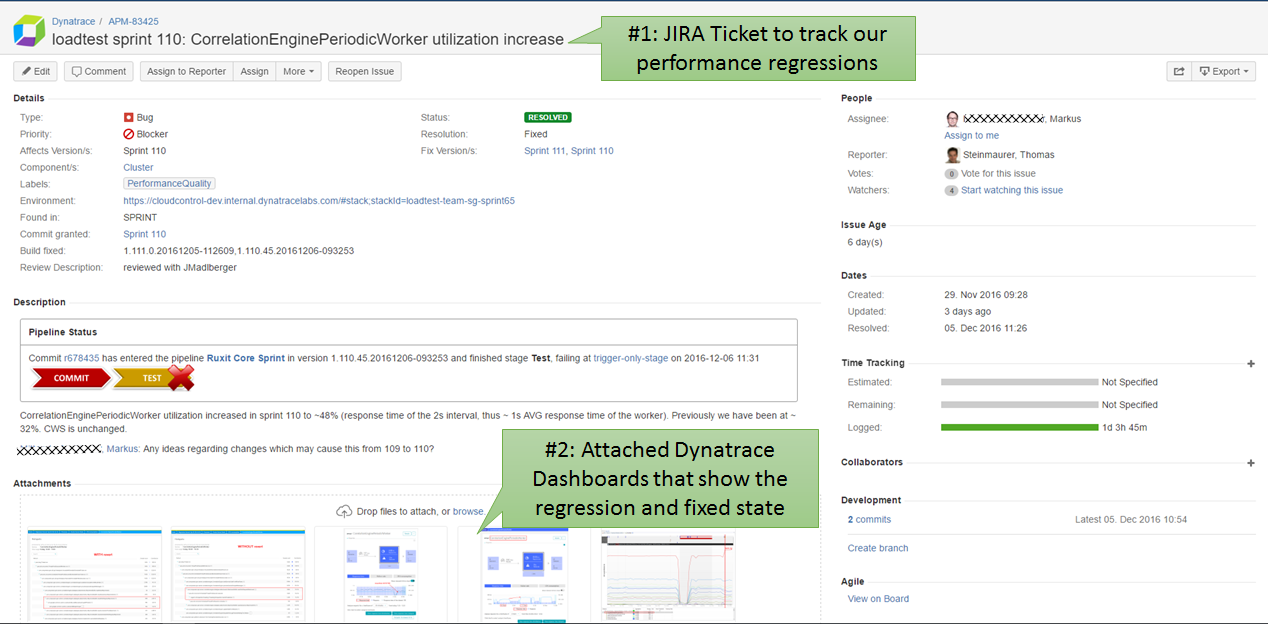
The following is a screenshot of a Jira ticket he used to track a recent performance regression:
Comparing Performance Signatures across Builds
Via our automated provisioning layer “Cloud Control”, Thomas deploys a new build into his Continuous Performance Environment every day. He runs different load patterns throughout the day, e.g: one that simulates high volume of PurePath related data vs. one that simulates a very high volume of infrastructure metrics. Both have different performance characteristics on the Dynatrace Server and the database back end due to the way data it must be processed.
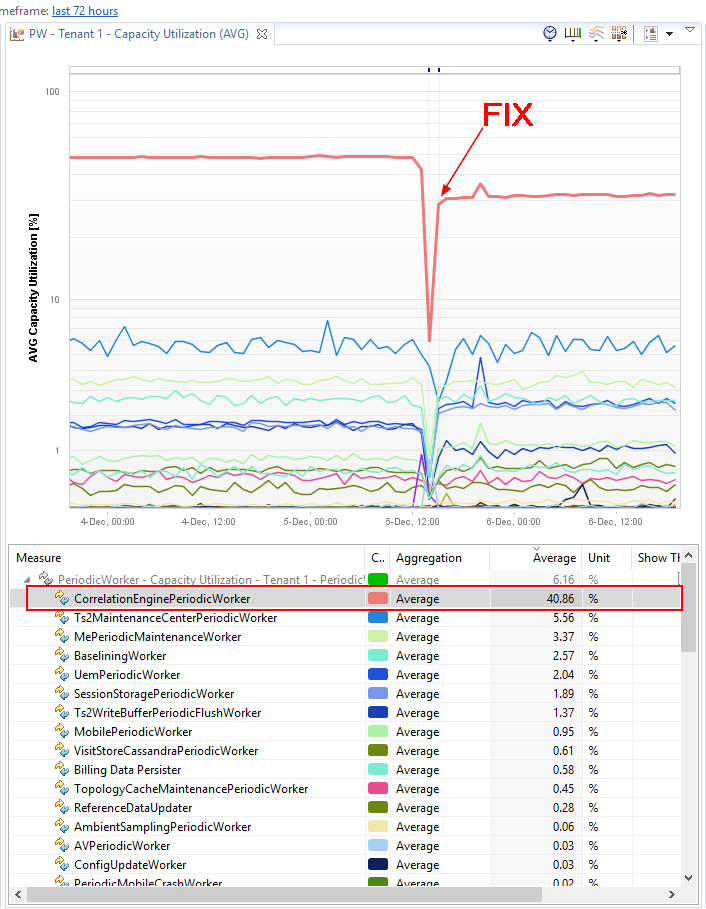
I asked Thomas: “So, how do you know a build has a performance regression?”. His answer was perfectly “phrased” when he showed me the following graph he pulled from Dynatrace:
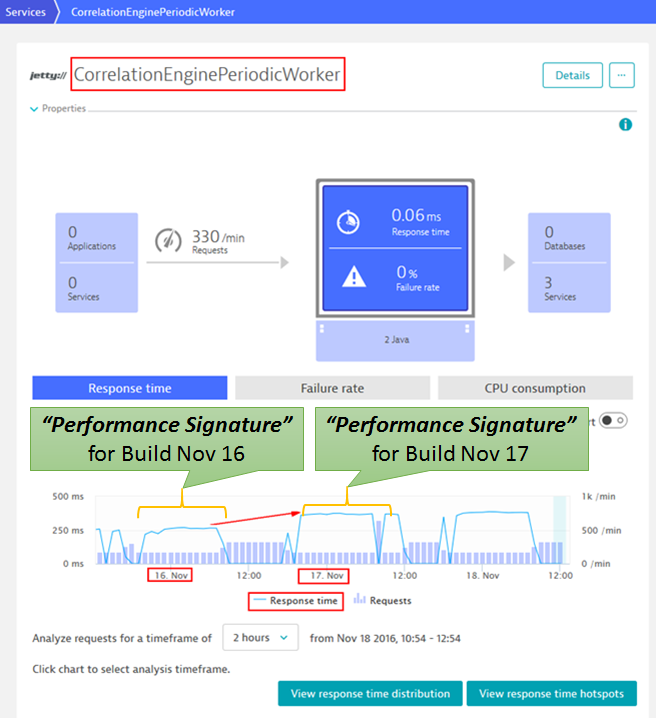
The dashboard above shows basic performance metrics for a “custom service” – the Correlation Engine Periodic Worker. You can see the marked timeframes on Nov 16 and Nov 17. These are the results when he ran the Load Test that had less throughput but required higher processing, thus resulting in a higher response time. However, the change that was introduced in Build Nov 16, deployed on Nov 16 evening and running overnight, clearly shows a totally different “Performance Signature” of the build. What is a “Performance Signature”? I must admit it is a term that our partners from T-Systems coined when they created the Dynatrace AppMon Performance Signature Plugin for Jenkins. I hope they don’t mind my “borrowing” this term but I think it PERFECTLY explains what we have to do in a Continuous Performance Environment. We need to “quantify” the Performance of the Service or Application Under Test is to compare it from build to build — these might be different metrics or a combination of metrics depending on what you are testing. From my perspective, the basic metrics should always be Throughput, Response Time, and Failure Rate. Additionally, we can add to these resource consumption metrics such as CPU, Memory, Network and Disk. The combination of these provides a “Performance Signature” that shows you “How Efficient Your Service/Application” is when processing a certain quantity of work load!
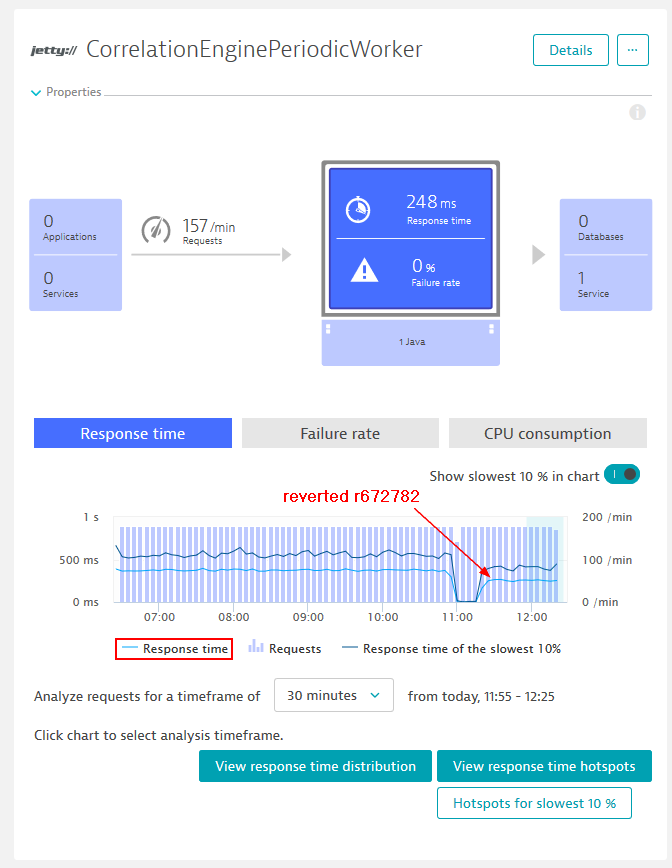
Quick Validation through Code Revert
When Thomas saw that performance wasn’t good in that build, he and the component owner had to investigate code changes between Nov 15 and 16. They did a quick sanity check by simply reverting the changes and running another test to validate that a recent architectural refactoring in that component was responsible for it. Thanks to the deployment pipeline and Cloud Control that was an easy thing to do. This is where automation pays off. And, as you can see from the following graph, performance was back to normal, proving that the code change that came in through one revision caused that issue:
Root Cause Detection
Just reverting is obviously not the solution to the problem. As Dynatrace captured detailed code level performance data Thomas simply compared code execution of the before and after the code change showing him – as an architect – where the introduced performance regression was:
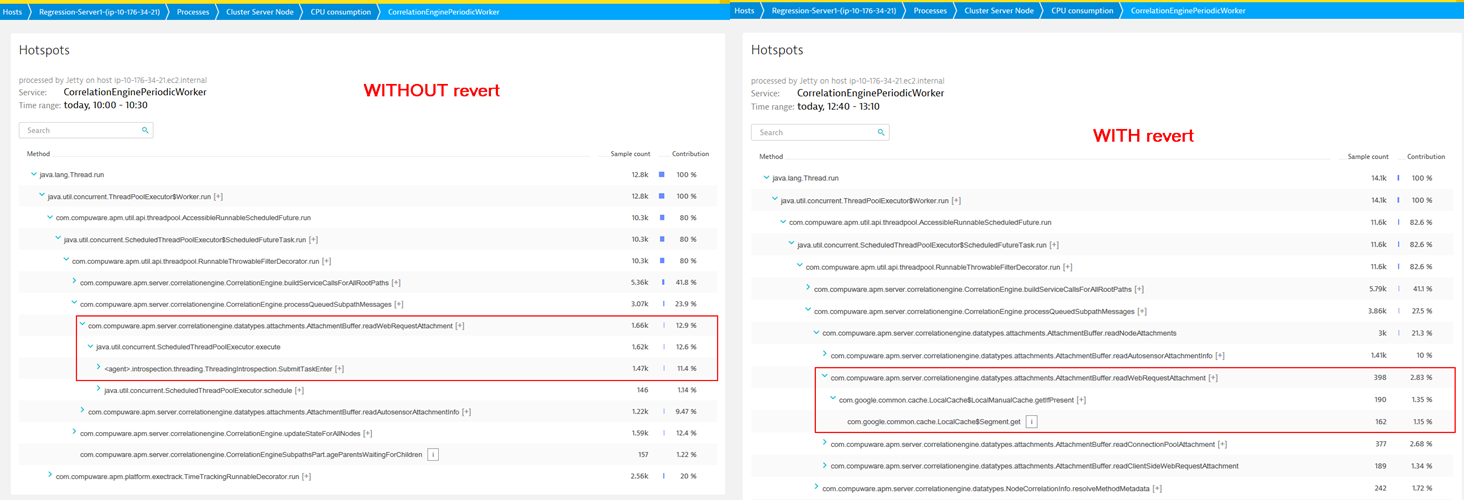
Now if you know the architecture and the code of your services and applications well enough, you immediately understand the root cause when getting this type of data presented side by side. The problematic version was simply bypassing a cache layer and always requesting data from the back end data store. That regression caused the performance regression.
The importance of JMX Metrics
While having the data available that Dynatrace captures by instrumenting your application, in this situation, actually instrumenting another instance of Dynatrace, it is very often important to look at additional metrics that are exposed by the application. In the case of Dynatrace the architects expose a lot of key performance and throughput metrics through custom JMX Metrics. Thomas and his colleagues have all assured me that they wouldn’t want to live without these custom metrics. This is also why they keep an eye on them. Both Dynatrace AppMon and Dynatrace have native support for capturing and charting these as shown in the following screenshot from a custom chart that Thomas reviews while his tests are executing:
Keeping track of Deployments and Test Executions
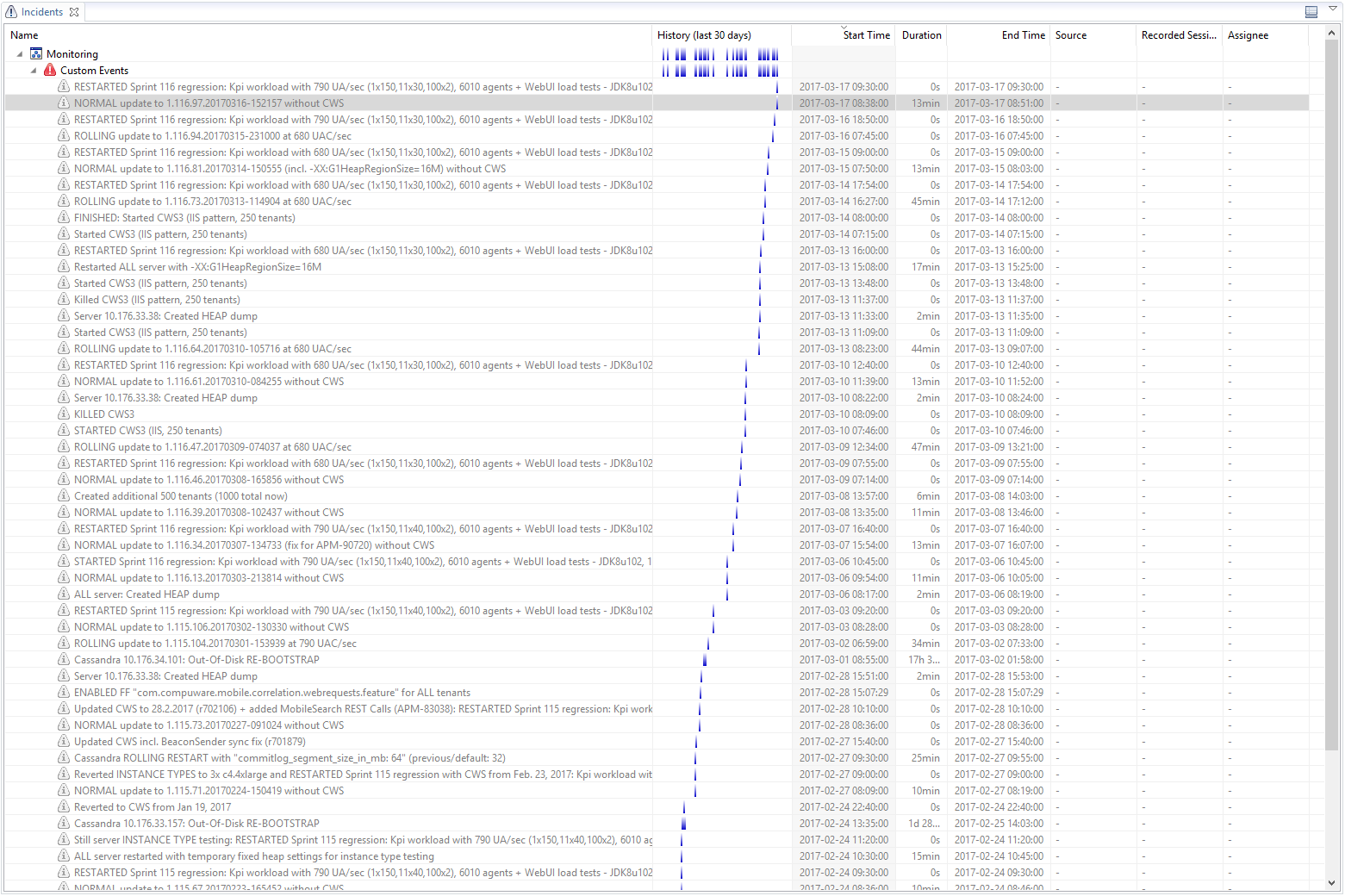
The last thing Thomas showed me is how he keeps track of the status in his continuous performance environment. He uses custom events that are supported by Dynatrace AppMon. Every time he starts or stops a load test, or when a new version gets deployed or when configuration/tuning settings are changed, he makes a REST Call to let Dynatrace know about that event. That makes it easier when analyzing data because you know about the actual environment configuration and load when analyzing the tests:
The power of Continuous Testing and Monitoring
Continuous Performance Testing makes it possible to detect performance regressions much faster than in traditional load testing environments where you run large scale load tests at the end of a sprint or release. In combination with Monitoring you can easily compare the “Performance Signature” across builds and provide feedback to your engineers minutes or hours after they made a code check in.
Thanks again to Thomas for sharing this story. Keep using our own products. Keep innovating by automating these feedback loops we so desperately need!
If you want to test Dynatrace on your own get your SaaS Trial by signing up here.

Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum