
If your VMware-hosted application struggles with poor performance, be aware that application performance depends not only on available CPU and memory resources, but also on disk I/O performance and network communication health.
How do I figure out the causes of poor performance?
Many tools facilitate the exploration of performance problems with respect to applications themselves. These tools typically monitor the performance of a single component, such as a database or an application container. There are also available tools that you can use to monitor your infrastructure (for example, VMware vSphere) and disk performance (for example, IOmeter).
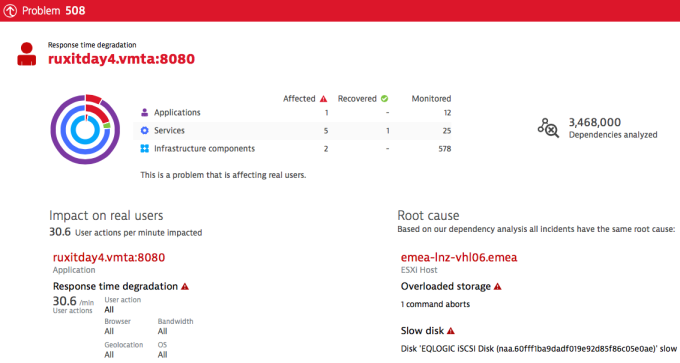
We found a problem that affects the user experience of one of our web applications. The application suffers from increased response times stemming from the fact that one of our ESXi hosts has slow disk performance and overloaded storage. This got me wondering about which metrics are most relevant to poor disk performance. Is throughput the main thing to focus on?
What are the key disk performance metrics?
In the case of virtualized infrastructure, as we have in our situation, multiple virtual machines make use of the same physical storage devices and consequently can negatively affect storage I/O performance. With this in mind, it makes sense to keep an eye on key I/O performance metrics if you want to keep your environment healthy and responsive.
Here’s my list of key disk performance metrics:
- Throughput (no surprise here)
- IOPS (also no surprise. We know these well from SSD manufacturers)
- Disk latency (DAVG – device average latency)
- Queue latency (QAVG)
- Aborted commands (ABRTS)
There are many other VMware-related storage metrics that you can consider. If you’re curious, refer to VMware’s own list of disk performance counters. However, in this blog post I’ll only go into detail regarding one of these metrics, disk latency.
Disk latency count
Disk latency measures the amount of time it takes a disk to complete a command. Many published articles have discussed optimal settings and response times related to storage environments. The lesson is clear: It’s hard to declare optimal threshold values for disk latency that are universally applicable. Though most recommendations for maximum threshold values for disk latency range from 15ms to 25ms.
These values don’t seem to be realistic. Based on our observations 15-25ms latency is not a problem. Values up to 50ms most applications can tolerate. The challenge is that threshold values are heavily dependent on the specific storage solution in use, I/O block size, the sensitivity of the application to I/O performance, and more.
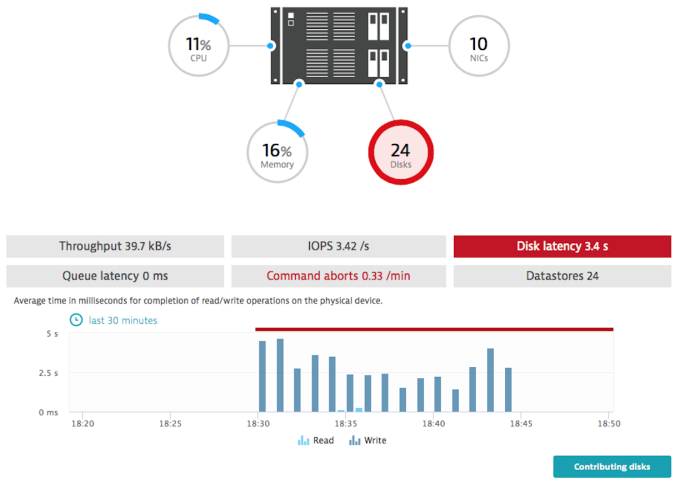
For the situation illustrated above, average disk latency is over 3.4 seconds for a short period of time. This is way too high compared to recommended values. Please note that the given metric value is a sum of all disks on this host; it represents the total of disk latency value.
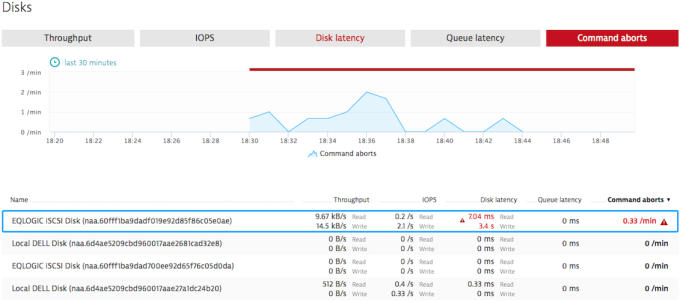
At the same time the number of command aborts has increased. This is a symptom of overloaded storage device caused by storage misconfiguration. Ideally, this value is zero.
How did we fix this problem?
Based on input from our infrastructure guys, the issue with high latency was caused by a corrupt physical disk and a misconfiguration of the controller. A disk within the array began to fail (and was eventually replaced). Also, the controller was set to “write-through” instead of “write-back,” which may have affected disk performance.
Wrap up
So, it’s not only CPU, memory, and network performance that you should look at when struggling with poor application performance. Quite often disk access turns out to be the bottleneck in your environment. Infrastructure monitoring has proved to be highly valuable in my analysis. It has shown me the impact that disk problems can have on the application level. I have to admit though, I’m a little biased since I work for this new player in the APM market.
Visit our dedicated web page about VMware monitoring to learn more about how Dynatrace supports VMware.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum