
In recent months, at multiple customers, I’ve had the opportunity to observe shockingly similar problems that follow an unfortunately common scenario:
- There is a perceived site issue
- A war room or incident is started
- The network is quickly thrown under the bus
- Why? Because the complaints are only coming from one site; therefore, it MUST be a network issue
This predicament results in the network team reeling backward as they scramble to find answers and prove innocence. Phone calls are made to vendors for IP accounting (which can take up to 48 hours to produce results), CLI windows fly open as engineers attempt to capture the evidence of the issue in real-time, and everyone on the war room call waits in a not-so-patient manner. Other teams may be status checking their systems, but only enough to be able to claim ‘all systems are operating normally’ when called upon. The entire investigation seems to crawl at a slow pace; either the data isn’t there, or if it is, it is merely a snapshot, or it lacks the relevant detail to definitively prove the network guilty or innocent.
If I could trademark a measurement for this activity it would be Mean Time to Innocence (MTTI). This would be a sub-metric to the more cumulative Mean Time to Resolution (MTTR) normally measured in these scenarios.
This got me thinking. Why is this such a challenge for organisations? Why were these network teams unable to swat away these claims of the network being the root cause when all the server guy had to say for his technology was ‘it’s on and available’? I think some of the issue is ownership. Most organisations don’t own their WAN, which is why we have Telecoms companies. Instead, they normally have limited read access to an edge router or to firewalls, and that is enough — until the next time the above situation happens.
The question remains; how do you reduce your MTTI (see it is slowly catching on)? The answer, fundamentally, is through effective monitoring. This opens the next can of worms — how and to what extent? The solution may not be as difficult as you might expect. As with any good solution you need to understand three things:
- What are the use cases you are looking to address?
- What types of data are available to you?
- What use cases can be addressed by what types of data?
Step 1 is quite easy to tackle. You can probably list off a few scenarios (I already alluded to one above) that come at you every time something goes pear shaped. Once you’ve had a brainstorm for all the scenarios you’ve encountered, or even better having looked into your ticketing system so you’ve backed up your list with data, then you’re ready to move on to step 2.
My brainstorm short list of use cases:
- Is my link available?
- What is my link utilisation?
- Who is causing the utilisation?
- How are they talking to each other?
- What application are they using?
- What transactions are they executing?
- Is my network the cause of the problem or simply a symptom?
Step 2 isn’t too hard to discover. A little Google searching or some casual conversations with your other networking buddies will tell you there are a few different options:
- NetFlow
- NetFlow leverages layer 3 and 4 packet header information, observed by devices in the network infrastructure, to determine usage metrics for specific applications defined by port number, which is exported from the device in the form of flow data. This flow data (i.e., periodic summaries of the traffic traversing an interface) is sent to a collector, which in turn might generate reports on traffic volumes and conversation matrices.
- NBAR2 (Network Based Application Recognition)
- NBAR relies on deep and stateful packet inspection on Cisco devices. NBAR identifies and classifies traffic based on payload attributes and protocol characteristics observed on the network infrastructure.
- Flexible NetFlow (FNF)/ IPFIX
- Flexible NetFlow and IPFIX are extensions to NetFlow, sometimes referred to as NetFlow v9 and v10. These extend the basic NetFlow concept by allowing the inclusion of extended metrics to be exported within the Flow sets. These metrics include those defined within NBAR2.
- Wire data
- Wire data simply refers to the extraction of useful information from network packets captured at some point on your network. While this includes insights from protocol headers, it generally implies deeper inspection of application payloads. Wire data is typically obtained via a port mirror or through a physical or virtual tap.
- A tap is sits in-path and provides exact copies of the actual packets on the wire, sending these to an aggregator, a probe, or a sniffing device.
- A port mirror, often referred to by its Cisco-centric term SPAN, follows a similar premise as a tap except that it is an active function of the network infrastructurePackets are copied from one or more device interfaces and sent out via another interface to an aggregator, probe, or sniffing device.
Step 3 is where all the fun is because it will ultimately help determine your solution. I created a matrix comparing use cases vs. data types.

Based on the above we can conclude that wire data has the most potential and should be used in the most critical places like in the data centre where your applications reside. For a branch office, you can gain broad insights using NetFlow and for more granular insight Flexible NetFlow/IPFIX and NBAR.1 If your monitoring solution can decode and analyse the application protocol.
Luckily for me, Dynatrace NAM allows us to accept all three types of data and uses the same reporting engine to display all of them making it easy to prove that MTTI.
Here are two NetFlow reports I specifically created for that use case I mentioned at the beginning.
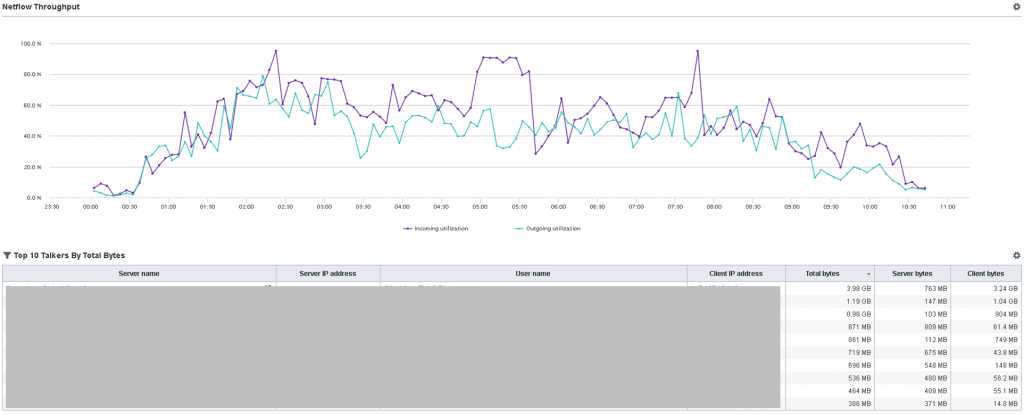
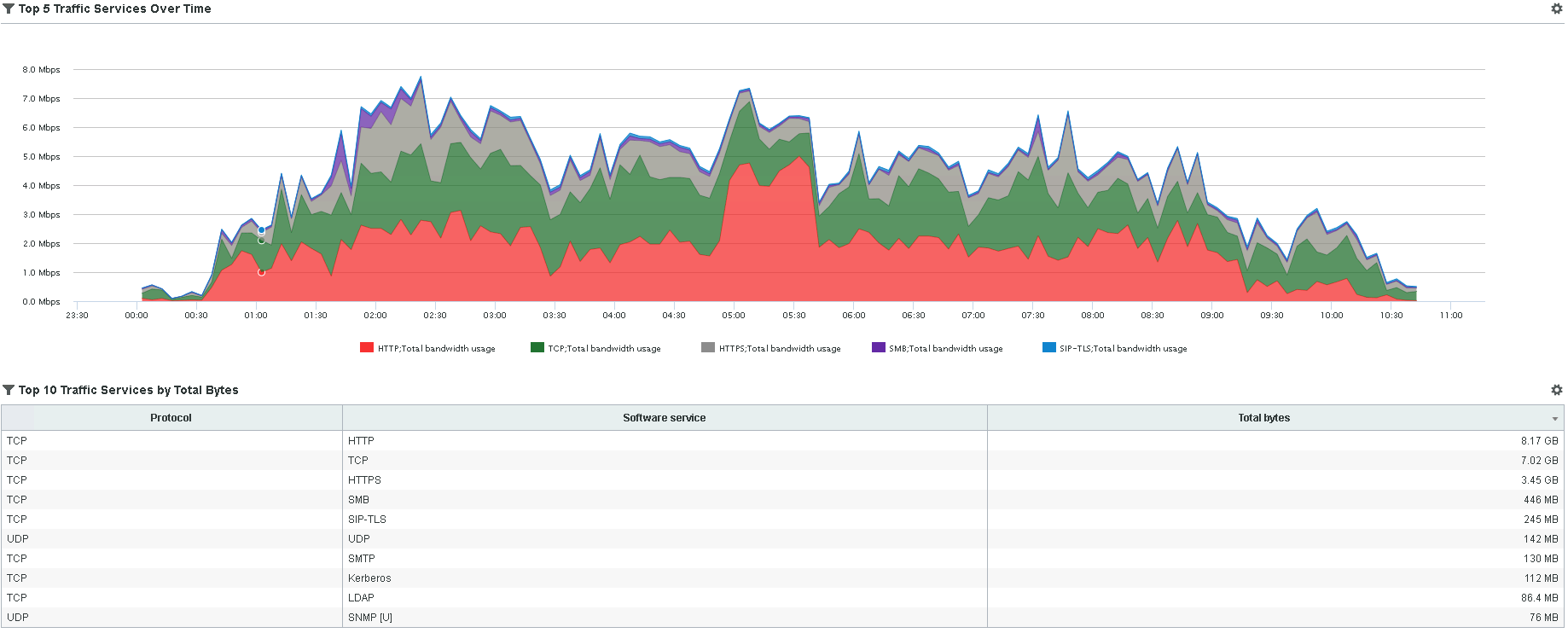
The client can easily answer those use cases mentioned in the matrix. In this example, I can see a spike that pretty much maxed out the link for a duration of 60 minutes from 4:45AM – 5:45AM. I can tell the IPs that caused that spike in the table of Figure 1 and I can tell that one type of traffic (HTTP) doubled during that spike (4:45AM – 5:45AM).
To address the other issue I was working on, I leveraged wire data and NAM’s SAP transaction-level decode. Two sites were having issues with their SAP ECC system. The perception, as I mentioned earlier, was that the network was the only cause. Letting NAM do the analysis work for me, I could see their problem pattern for slowness changed considerably after the 29th. The problem was dual-edged. While they had earlier addressed the client issue (shown in yellow), NAM now pointed towards data centre tiers being the issue (sorry server guy).
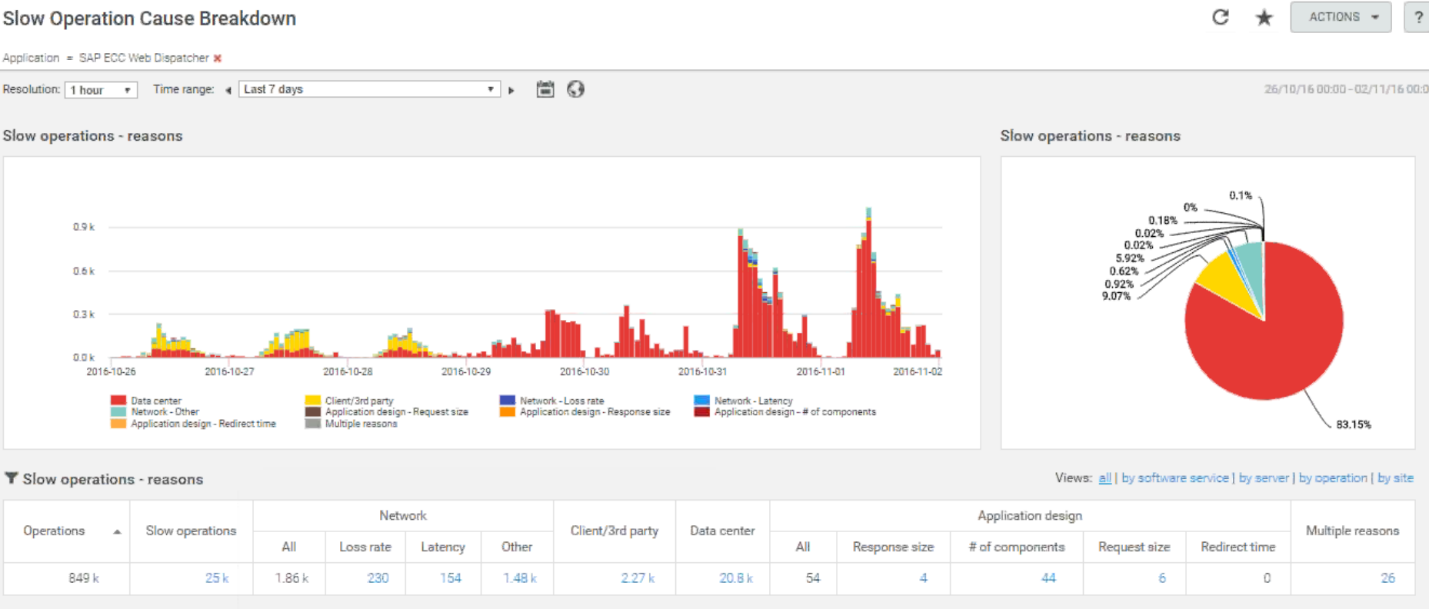
Drilling into a single T-code (the name for SAP transactions), the issue was very apparent. Almost all of the transaction delay was on the server side.
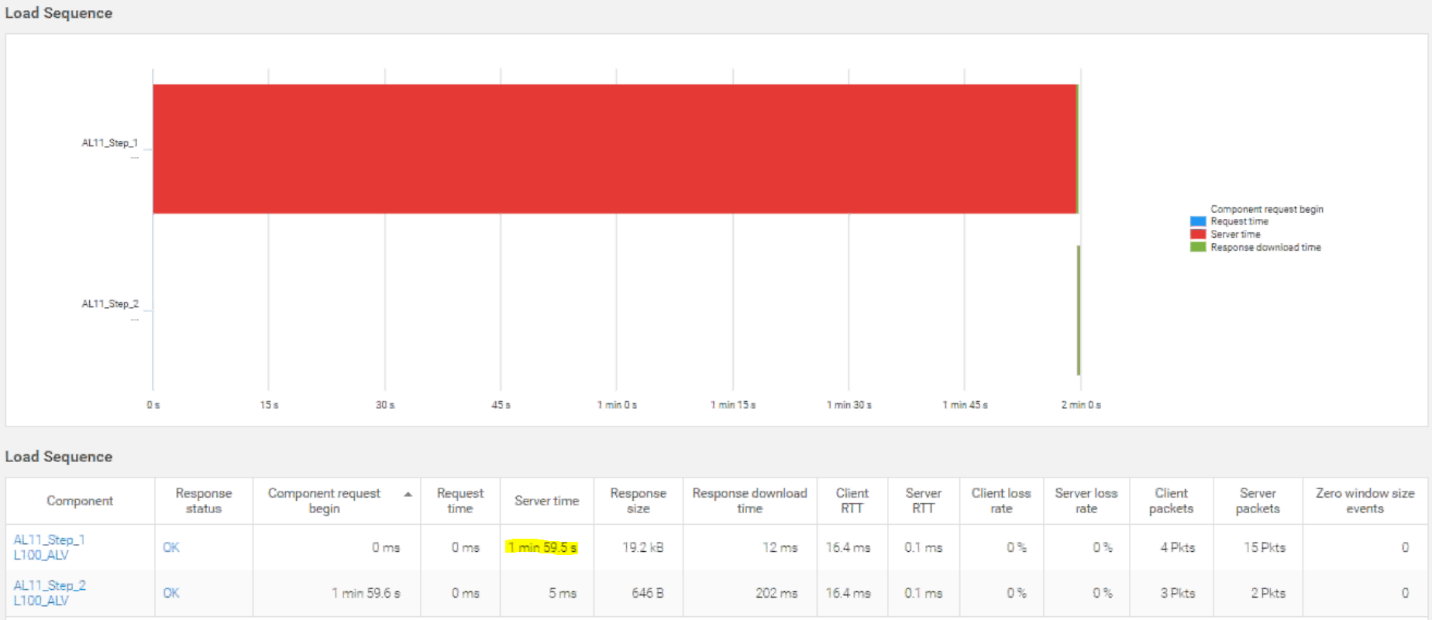
You can see the clear difference in data types. In the NetFlow example we can see symptoms: high link utilisation, HTTP traffic volume increase, etc. but NetFlow’s lack of application-level insights limits our ability to isolate a fault domain. Yes, there was a sustained spike, but it is difficult to derive what was causing the incident and how many it affected. While the analysis did reduce our MTTI and possibly our MTTR, it didn’t provide enough detail to effectively isolate the fault domain.
In the wire data example, you can begin to appreciate the clarity gained by decoding individual transactions – in this case, for SAP. Not only could we see that the issue was dual-pronged, we could clearly articulate the issues with information that makes sense to everyone. We’ve captured the user’s login name, identified the transaction by its meaningful name (L100_ALV is the SAP transaction ID), its precise duration (2 minutes), and the distribution of delays (99% server time!), and are able to direct the investigation accordingly. This changes the dynamic of the war room from defensive – trying to prove your innocence – to collaborative, driving rapid positive results.
Whether you are looking to invest or expand in a product suite soon, I urge you to run through a similar exercise to evaluate how your product selection could address your specific use cases. Don’t just look at the answers the products give you. Interrogate how they analyse that data type, if at all, to get you to that resolution. Application awareness (i.e. NetFlow/NBAR2) and transaction fluency (i.e. wire data with analysers for application-specific protocols and behaviors) are two completely different things and should be well studied when considering your next-generation monitoring solution.
Now, off to patent that metric…




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum