
The ability to automatically and reliably deploy entire application runtime environments is a key factor to optimizing the average time it requires to take features from idea to the hands of your (paying) customers. This minimization of feature cycle time or feature lead time is, after all, the primary goal of Continuous Delivery. Today, I will introduce you to the whys and wherefores of deployment automation and discuss its importance for driving the adoption of DevOps.
The Power of Automated Deployments
Production servers can be described as “grown works of art”: An unknown number of commands have been applied by various people over time, often in an ad-hoc manner, and written documentation is commonly outdated, if at all present.
Due to the inability to fully understand and entirely reproduce such environments, companies periodically create full server backups to be prepared against server loss. Still, restoring an environment from backups may consume considerable resources with uncertain success (how frequently do you verify your backup strategy and assess the mean time to recover?) and can by no means be compared with the flexibility and agility of being able to rapidly and reliably re-create any environment on-demand – from development to production:
“Enable the reconstruction of the business from nothing but a source code repository, an application data backup, and bare metal resources.”
Adam Jacob, CTO of Opscode
Continuous Delivery embraces automated deployments in various stages of the software delivery process and identifies manual deployments as one of the common release anti-patterns. It demands to let computers do what computers do best. Therefore, over time, all deployments should be fully automated to make releasing software a repeatable and reliable push-button activity:
- manual deployments are not consistent across environments
- manual deployments are slow, neither repeatable nor reliable
- manual deployments require extensive documentation (often outdated)
- manual deployments hinder collaboration (usually conducted by a few experts)
In combination with Agile development practices and a sound suite of automated tests, deployment automation allows you to minimize feature cycle time or feature lead time by reducing waste. No doubt, time-to-market is important if not vital: you will not know whether your users will adopt a new feature before you actually let them try it out, and the sooner you deliver the earlier you can start to make money out of it:
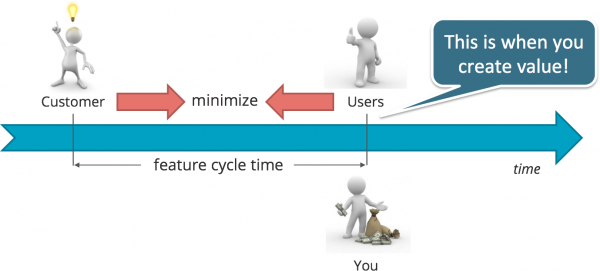
Another common anti-pattern is “deploying to a production-like environment only after development is complete.” This means there can be almost no confidence that a particular software release will work successfully for end users if it has never been tested in a copy of production.
We will now examine how deployment automation fits into the concept of a Continuous Delivery deployment pipeline because it lays an important foundation for establishing a high degree of confidence through the automated provisioning of production-like environments.
Deployment Automation in the Continuous Delivery Deployment Pipeline
As Jez Humble and Dave Farley put it in their seminal book “Continuous Delivery,” “A deployment pipeline is, in essence, an automated implementation of your application’s build, deploy, test and release process.”
The pipeline concept itself is in analogy to Lean Manufacturing, where a production line is stopped whenever a defect is detected along its way. The problem is then addressed with immediate and utmost attention and corrective measures are taken to minimize the possibility of making the same mistake ever again (Continuous Improvement) – a principle that is crucial in Agile Software Development.

Here is what a deployment pipeline could look like for your application. In general, the process is initiated whenever a developer commits code to a software repository inside the version control system (VCS) such as Subversion or Git. When the build automation server, which acts as the pipeline’s control center, such as Jenkins, observes a change in the repository, it triggers a sequence of stages which exercise a build from different angles via automated tests, but terminates immediately in case of failure. Only when a build passes all stages it is regarded to be of sufficient quality to be released into production.
Stage #1: Commit Stage
In the commit stage, the build automation server checks out the software repository into a temporary directory, compiles the code and executes any quick running, environment agnostic tests (mostly unit tests). After that, release artifacts such as installer packages are assembled and documentation is generated.
Stage #2: Acceptance Test Stage
In the acceptance test stage, deployment automation scripts (executable application runtime environmental specifications) are executed to create an environment that is dedicated to the remainder of this stage and that is highly similar, not necessarily identical, to the production environment. Release artifacts are deployed and smoke tests are executed to verify that the application and related services are up and running. Finally, automated acceptance tests are run to verify the application at the business level where it is asserted that the application conforms to business critical customer acceptance criteria.
Stage #3: Capacity Test Stage
Similar to stage two, but automated capacity tests, typically load tests, are run to verify that the system can serve a defined level of service under production-like load conditions. Here, it is assessed whether the application is fit for purpose from a non-functional perspective, mostly in regards to response time and throughput.
Stage #4: User Acceptance Test Stage
In this stage, the customer performs manual user acceptance tests as a final verification step.
Stage #5: Release Stage
After having passed all of the previous stages, a successful build is made available in a binary repository, such as an Artifactory, from where it can be released into production whenever the business is ready: in Continuous Delivery, as opposed to Continuous Deployment, releasing a build into production is still a semi-automatic process that should require you to do exactly two things: select a build from a list and press the release-button.
How Deployment Automation Avoids Drifts in Environments
Upon release, the production environment is provisioned using the same process (with the same deployment automation tools and scripts) that was used to provision the production-like environments that successfully probed the selected build. To cater for this tight relationship between your ever-changing application and the infrastructure it runs on, your application source code needs to be maintained together with your environmental specifications and be kept in a single repository.
Now, while treating infrastructure as code certainly requires a change in the way you think about your infrastructure, it also opens up a great opportunity: to establish a culture of change and mutual respect between development and operations teams that results in a collaborative and efficient working relationship.
How Deployment Automation Drives the Adoption of DevOps
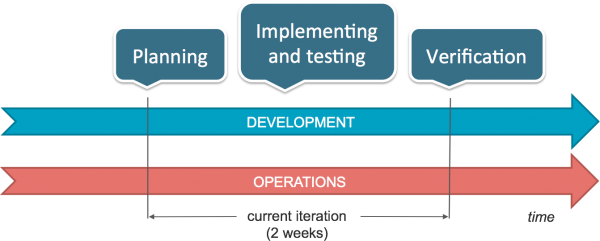
Development teams are driven by customer demand. Infrastructure as code enables you to treat the development of your automated deployment process as an engineering discipline, driven by software development: at the beginning of an iteration, the team leads of the development and operations teams get together in a planning meeting to jointly define the tasks that need to be done. During an iteration, each team implements and tests its tasks before their correct behavior is demonstrated and verified in front of a greater audience (preferably in front of the customer). In a retrospective meeting, the teams discuss what went well, what went not so well and in which ways the workflow could be improved. By enforcing an automated deployment process and treating infrastructure as code you make sure that you end up with deployable code and working environments at the end of each iteration.
From a business perspective, deployment automation allows you to get changes, whether planned or unplanned, into production reliably and quickly. This allows you to gather precious user feedback (which could be as simple as monitoring your users clicking on that “use this new feature” button) as early as possible and develop and maintain software that is lean and that offers features that your users like to use, thereby avoiding software bloat.
If you think that deployment automation is something for you, stay tuned for an upcoming article where we will look at the topic from a mere technical perspective and conclude with the dissection of a real-world example of ours that automatically deploys our Dynatrace OneAgent into an application using Ansible.

Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum