
Why bother? That is the question many IT professionals face when trying to sell the value of application performance management internally to their organizations. As a working IT manager, for a Fortune 500 company, I like to save my company money, work more efficiently, and ensure that my system users are happy. It sometimes feels easier to not bother, but then inevitably there is a system failure, a group of unhappy users, or some type of technology emergency.
APM (Application Performance Management) for me makes it clear to every stakeholder whether your business runs well or not and who has to take action to fix this problem. The following screenshot shows a typical high-level APM dashboard with key application performance & business metrics that tell you whether you have to take action or not:
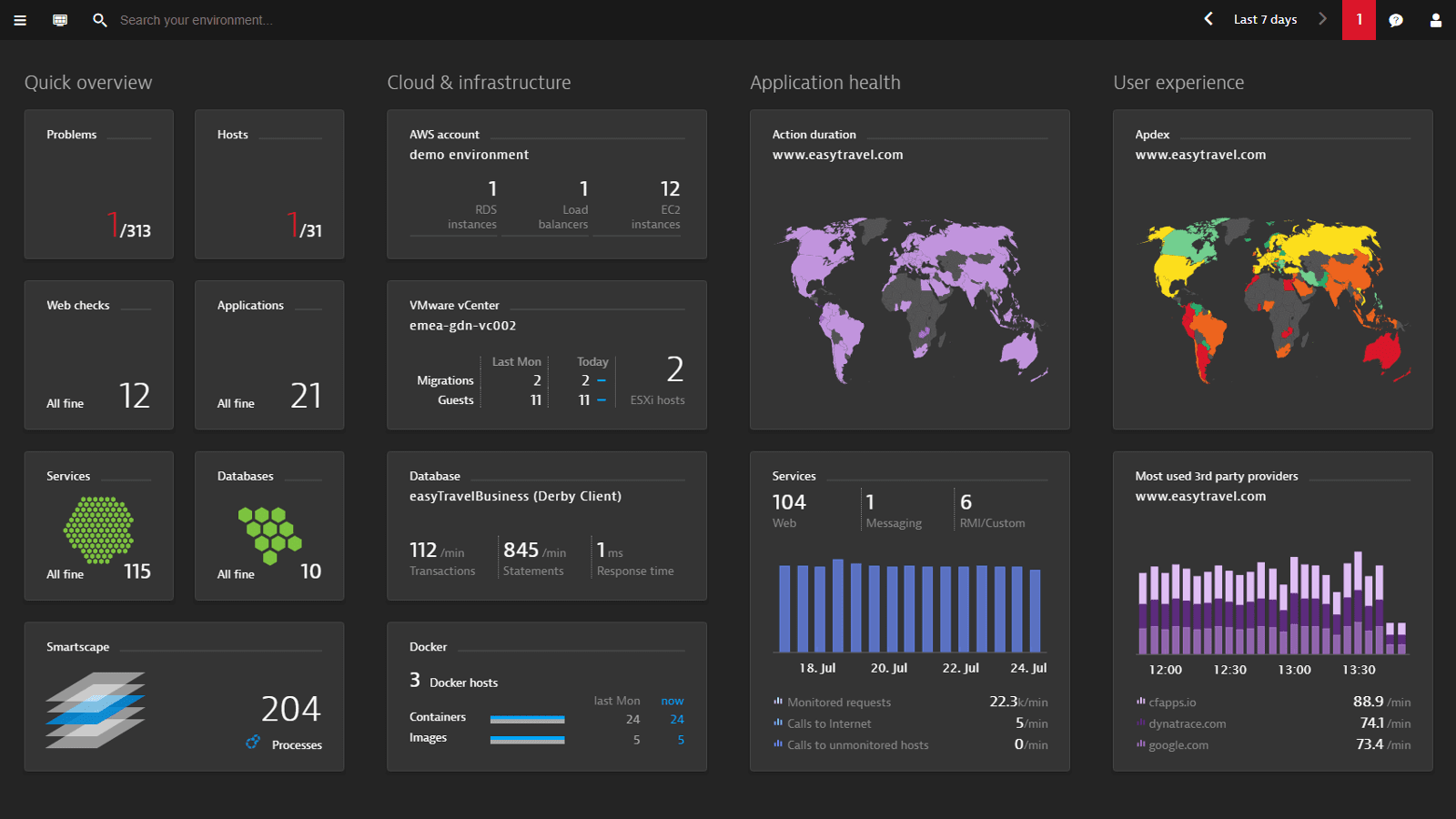
Why we looked into APM! Metrics it is!
Most frequently, it starts when users experience suboptimal performance. It could be a problem with the Network, OS, Middleware, DB or even just bad code. Without some type of monitoring these events (user complaints) turn into a time wasting multi-group troubleshooting exercise. Before you know it, these exercises steal valuable resources from other projects and other day-to-day activities. Let’s face it, by the time you get everyone on a call or even in the same room the major symptoms are gone and performance is almost, if not all the way, back to the user’s acceptable level.
This leads to the question, “Where do we start looking and whose system or component was to blame?” This ultimately, in most cases, leads to each group saying “my area looked fine during this time” and no real root cause is reached. But, the fact of the matter is that something was not performing at expected service levels, and we can be assured it will happen again. This also leads to the question “What do we tell the customers?” It’s fine to say we have a team on it, but at the end of the day if nothing gets resolved having a team on it means nothing. Most of the time users are not very understanding and IT can quickly lose credibility in its ability to deliver.
Wouldn’t it be great to have the ability to track a single (or group of) users through your system while viewing live and past data of all the different web calls, DB calls and even network hops? Wouldn’t it even be better to have the ability to see if the issue is even in our network or the clients’? This is the value! This is why we should bother with APM!
APM gives us the ability to baseline user experience and notify IT if we are moving out of our overall response time agreements. This gives IT the ability to quickly isolate what or where the issue is coming from and to pinpoint how many users are really affected. APM decreases the need to create “war rooms” and gives you the knowledge to involve the right group of people to resolve the issue. This also gives IT the ability to proactively notify affected users and potentially-affected users about system problems and let them know that a resolution is in process. Front-line staffs, taking complaint calls are prepared with useful information to relay to the user along the lines of… “We noticed this issues a few minutes back and IT is actively working to resolve the problem. Thank you for reporting this and we will alert you once performance levels are back to normal”. Isn’t that better, that having them respond “Oh, okay. I will let IT know there is a problem”?
This proactive approach builds user confidence because users realize that the IT organization already knew about the issue and was working to fix the problem before the user had to report any concerns. It also gives users confidence that the IT organization actually cares about their experience and values their time. Of course, all this goes downhill if IT still can’t resolve the issue, but my point is that knowledge and proactive behavior are always better than a “why bother?” approach.
Success with APM – Making it Matter for Your Organization
Want to change your organization? Check out these 7 reasons that helped our organization see the value in APM to become a better overall IT Organization:
1: Learn your environment
This is the first step in any APM implementation. APM helps you learn your application flows, how the application runs, and who is using it. APM helps IT – and management – become familiar with different usage volumes (e.g. middle of the afternoon v. midnight). And it helps with the scheduling of resource-intensive jobs and capacity planning.2: Proactive approach to system management
Management loves “proactivity.” Once you understand how your environment runs, you can now start to be proactive in stopping problems in their tracks. This is not instantaneous but makes the result worth the effort.3: Reduction in staffing needs to support overall environments
Once you understand your environments and have proper monitoring and alerting in place, you will no longer need multiple people validating/monitoring the systems. You will still need staff to react to alerting, but the bodies needed to perform these actions should be minimal. This also allows your more senior employees to focus on project work, leaving day-to-day operations for more junior staff to attend to.4: Isolation of environment inefficiencies
Once you reach the stage of being proactive, you will also find the inefficiencies in your environments. Examples of this include looping code or even the excess DB calls you did not know about, not to mention things like extra network hops.5: Increased customer satisfaction
Increasing customer satisfaction, both internal and external, is a major goal of APM. Customers are the life blood of any system. As you increase the efficiency of your systems, you increase the efficiency of your customers resulting in higher customer satisfaction and retention.6: Build credibility with the user community
It takes time to build credibility but takes almost no time to lose it. As we get better at being proactive and communicating problems to our customers, we start building their confidence and ultimately breaking any negative perceptions of the company or IT.7: No more fire-fighting
Instead of getting all the application teams in one room, only bring in who is needed. Effective APM tools will point you to the pain point and allow only the required personnel to troubleshoot and fix the issue. This allows the workforce to continue focusing on other projects and taking on new responsibilities, with ‘firefighting’ handled by junior staff.With any solution, you need alerting capabilities along with some kind of ticket tracking system. Proper alerting decreases the need to have people physically watching the system. And, ticket tracking can help you determine if you are moving in the right direction (decreased incidents and user complaints). Tracking is also important for identifying re-occurring problems that need addressing.
Some examples of alerting/notification include Email, Central dashboards for NOC and/or Administrators, and Integration into Service Now (Ticket tracking).
APM Tools like Dynatrace offer the ability to see all Network related traffic (HTTP, HTTPS, SOAP, XML, DB calls, etc.) passively. These tools allow the creation of a baseline for all traffic types, giving IT the ability to see what is normal and what is not. It also gives IT the ability to track a single user or a group of user requests and isolate where the slow call(s) happened or where the error(s) came from.
Tools like Dynatrace give IT the ability to watch transactions through the actual code running on the server. IT can create “Business Transactions” and start baselining response times on all requests coming into each and every single server. This type of monitoring provides the ability to isolate slow DB (or bad SQL) calls, show where the code can be tightened up or needs to be adjusted, how many different systems are involved in a single transaction, which server is having slow performance compared to the others, and how many users are being affected. IT now has the ability to start monitoring middleware, infrastructure and code base from a single spot while also giving us the ability to start tracking Revenue vs Performance. The following screenshot is showing the value of having full end-to-end visibility with APM.
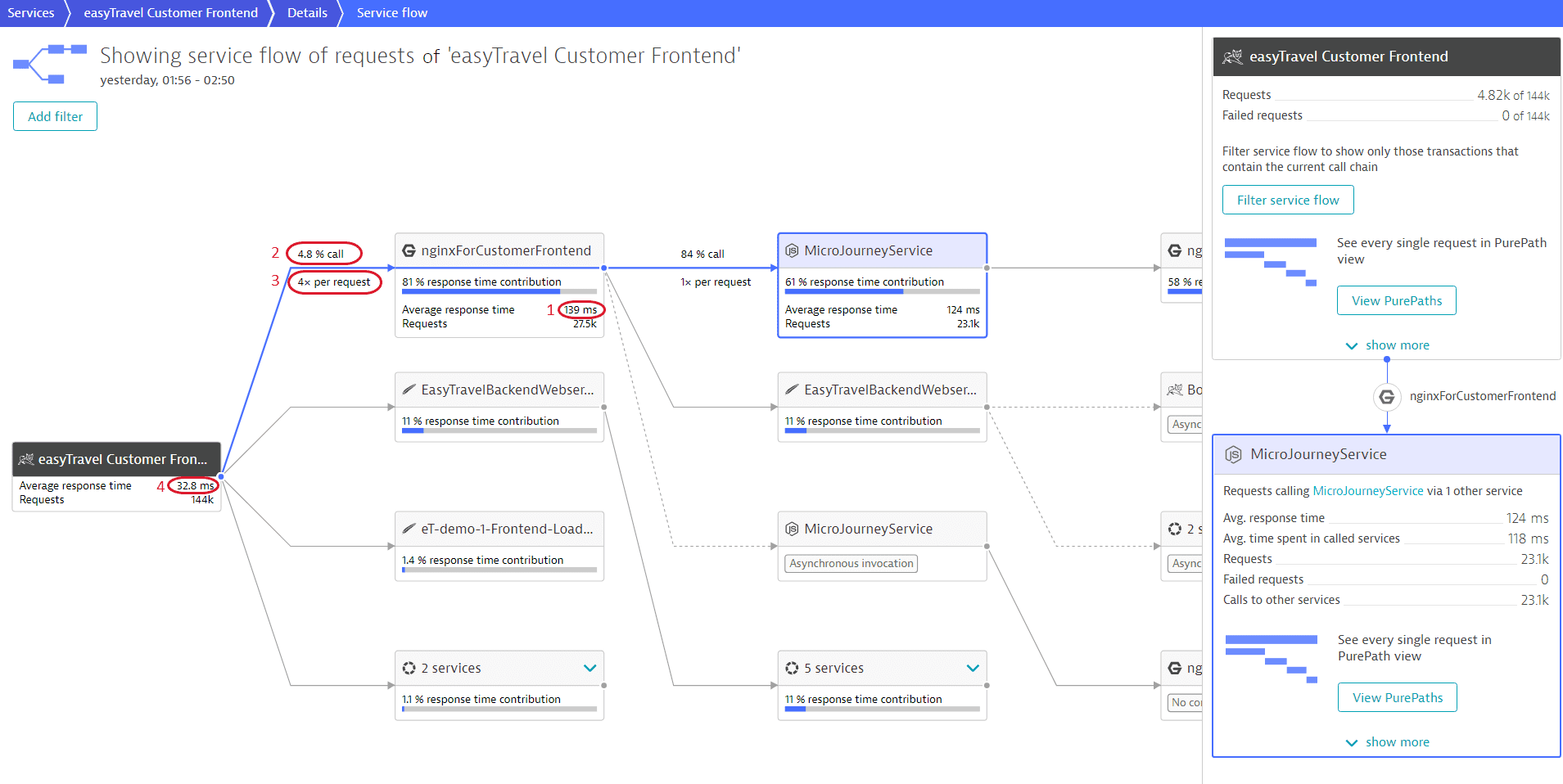
APM seems like a no-brainer to me.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum